
AI Red Teaming

AI Red Teaming, znane również jako LLM Red Teaming to proces testowania bezpieczeństwa, który symuluje rzeczywiste ataki na systemy oparte na sztucznej inteligencji, w szczególności wykorzystujące duże modele językowe (LLM). Jego celem jest identyfikacja podatności, możliwości nadużyć oraz ocena ryzyka biznesowego.
W przeciwieństwie do tradycyjnych testów penetracyjnych, AI & LLM Red Teaming koncentruje się na tym, jak modele sztucznej inteligencji zachowują się i reagują na polecenia oraz w jaki sposób wchodzą w interakcję w użytkownikami. Obejmuje to testowanie pod kątem prompt injection, manipulacji modelem, wycieku danych oraz niewłaściwego wykorzystania w rzeczywistych kontekstach.
Rosnąca rola sztucznej inteligencji i narastające obawy dotyczące bezpieczeństwa
Duże modele językowe (LLM) oraz inne generatywne systemy sztucznej inteligencji trwale odmieniły strukturę technologiczną. W miarę ich rozwoju wprowadzane są nowe mechanizmy, takie jak Retrieval-Augmented Generation (RAG) oraz Model Context Protocol (MCP), które mają na celu dalsze zwiększenie możliwości LLM-ów i rozszerzanie ich funkcjonalności poza dotychczasowe ograniczenia.
Im bardziej złożone stają się te systemy, tym większa jest ich potencjalna powierzchnia ataku. Dlatego coraz więcej firm wyraża obawy związane z zagrożeniami ze strony sztucznej inteligencji. Zgodnie z raportem “The Artic Wolf State of Cybersecurity 2025 Trends Report”, 29% liderów ds. bezpieczeństwa wskazało AI, duże modele językowe (LLM) oraz kwestie prywatności jako główne zagrożenia dla cyberbezpieczeństwa, czyniąc je priorytetowym obszarem zainteresowania.

Według raportu “HiddenLayer 2025 AI Threat Landscape”, 89% liderów IT uznaje większość lub nawet wszystkie modele AI wdrożone w produkcji za kluczowe dla sukcesu swojej organizacji. Mimo to wiele firm nadal działa bez kompleksowych zabezpieczeń. Szacuje się, że zaledwie 32% z nich wdrożyło rozwiązania technologiczne mające na celu przeciwdziałanie zagrożeniom związanym ze sztuczną inteligencją.
Co więcej, niemal połowa organizacji (45%) nie zgłosiła incydentu związanego z bezpieczeństwem AI z obawy przed szkodą dla reputacji.
Skontaktuj się z naszym ekspertem!

Należy nieustannie wzmacniać poziom bezpieczeństwa rozwiązań opartych na sztucznej inteligencji, ponieważ z perspektywy organizacyjnej stają się one kluczowymi zasobami.
Testowanie bezpieczeństwa AI & LLM (GenAI)
Zgodnie z przewodnikiem OWASP GenAI Red Teaming, Red Teaming dla systemów generatywnej sztucznej inteligencji to uporządkowana praktyka polegająca na symulowaniu zachowań przeciwnika wymierzonych w systemy GenAI, takie jak duże modele językowe (LLM), w celu wykrycia słabości wpływających na ich bezpieczeństwo, niezawodność i zaufanie. Przyjmując perspektywę atakującego, możemy ujawnić potencjalne problemy, zanim doprowadzą one do poważnych konsekwencji.
AI & LLM Red Teaming, jako uzupełnienie tradycyjnego testowania bezpieczeństwa, analizuje, czy zachowanie lub odpowiedzi generatywnego modelu mogą prowadzić do niezamierzonych konsekwencji, w tym do generowania treści szkodliwych, nieetycznych lub niestosownych. Co więcej, testy te pozwalają również ocenić skuteczność zabezpieczeń stosowanych w dużych modelach językowych, takich jak ograniczniki (guardrails), filtry treści oraz inne techniki łagodzące, w rzeczywistych scenariuszach, aby zapobiegać niewłaściwemu wykorzystaniu sztucznej inteligencji.

Wszystko to sprawia, że AI & LLM Red Teaming staje się nieocenionym narzędziem do oceny poziomu bezpieczeństwa systemów generatywnej sztucznej inteligencji.
Dlaczego testowanie AI jest inne?
Tradycyjne metody testowania i zapewniania bezpieczeństwa nie są już wystarczające w kontekście rozwiązań opartych na sztucznej inteligencji. W przeciwieństwie do klasycznego oprogramowania, systemy generatywnej sztucznej inteligencji wprowadzają nowe poziomy ryzyka, które są dynamiczne, niedeterministyczne i często niemożliwe do wykrycia przy użyciu standardowych technik testów penetracyjnych.
Testowanie musi zatem ewoluować i powinno odzwierciedlać rzeczywiste zachowanie GenAI oraz typy zagrożeń, jakie za sobą niesie.
Nasze podejście do testowania
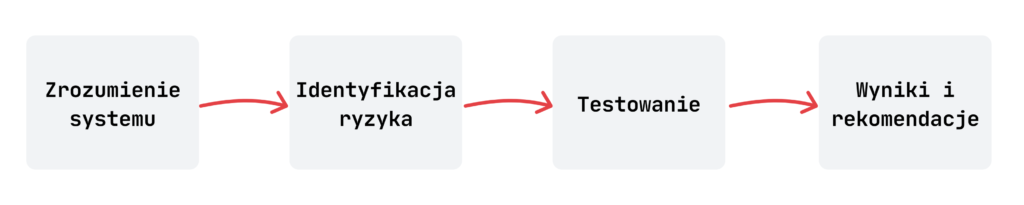
W ramach naszego procesu testowania stosujemy kompleksowe podejście do oceny bezpieczeństwa systemów opartych na sztucznej inteligencji. Na początku analizujemy architekturę systemu, aby dokładnie zrozumieć jego komponenty, przepływy danych oraz kluczowe zasoby. Taka analiza pozwala nam dostosować ocenę pentestową do unikalnych cech konkretnego systemu.
Następnie przeprowadzamy testy z zakresu modelowania zagrożeń. Robimy to zarówno we współpracy z klientem, jak i wewnętrznie, chociaż zdecydowanie preferujemy podejście kooperacyjne. Na tym etapie identyfikujemy potencjalne zagrożenia i ryzyka specyficzne dla analizowanego systemu, uwzględniając jego architekturę, funkcjonalność oraz scenariusze użycia. Oceniamy ich potencjalny wpływ oraz analizujemy możliwe strategie łagodzenia, które pozwalają ograniczyć prawdopodobieństwo wystąpienia lub skalę skutków tych zagrożeń.
Kolejno przeprowadzamy zarówno testy automatyczne, jak i manualne, koncentrując się na biznesowym celu systemu, aby objąć całą potencjalną powierzchnię ataku. Podczas działań Red Teamu wykorzystujemy informacje zebrane na etapie modelowania zagrożeń, aby ukierunkować i priorytetyzować nasze działania testowe, zapewniając ich zgodność z wcześniej zidentyfikowanymi ryzykami.
Na koniec dostarczamy szczegółowy raport zawierający zidentyfikowane podatności oraz rekomendacje dotyczące ich eliminacji. Raport obejmuje również wyniki fazy modelowania zagrożeń, co pomaga klientowi w dalszym wzmacnianiu ogólnego poziomu bezpieczeństwa jego systemu.

W całym procesie opieramy się na najnowszych standardach bezpieczeństwa oraz najlepszych praktykach dotyczących systemów AI / ML / LLM, takich jak OWASP TOP 10 Large Language Model Applications, OWASP GenAI Red Teaming Guide, MITRE ATLAS lub Google’s Secure AI Framework (SAIF).
Faza I – modelowanie zagrożeń
Jeśli znasz już naszą usługę modelowania zagrożeń, to wiesz, czego możesz się spodziewać. Będzie to wysoka jakość, indywidualnie dopasowane podejście, dostosowanie do konkretnego systemu oraz kontekstu biznesowego. W przypadku modelowania zagrożeń dla systemów AI koncentrujemy się na ryzykach charakterystycznych dla sztucznej inteligencji, takich jak generowanie niezamierzonych treści, podatności na ataki typu prompt injection, wycieki danych czy nieprzewidywalne zachowanie modelu.
Zazwyczaj proces modelowania zagrożeń przeprowadzamy we współpracy z klientem, co pozwala nam na dogłębne zrozumienie architektury systemu, przepływu danych wejściowych i wyjściowych oraz rzeczywistych scenariuszy jego wykorzystania. W razie potrzeby wykonujemy również analizę wewnętrznie, angażując zespół ekspertów Securing, posiadających doświadczenie w testowaniu i zabezpieczaniu systemów opartych na sztucznej inteligencji.
Naszym celem jest identyfikacja potencjalnych wektorów ataku, ryzyk i zagrożeń, a w konsekwencji ocena poziomu bezpieczeństwa systemu AI.

Faza II – testy bezpieczeństwa

Na początku procesu testowania bezpieczeństwa zapoznajemy się z systemem AI, przeprowadzając rekonesans. Obejmuje on analizę tego, jak w praktyce przebiega komunikacja z modelem, jak model reaguje na podstawowe zapytania oraz jakie dane są do niego przesyłane zarówno na poziomie promptów, jak i za pośrednictwem API. Weryfikujemy również, jakie funkcje oferuje aplikacja oraz czy model zachowuje się zgodnie z oczekiwaniami. Choć wiele z tych działań koncentruje się na samym modelu AI, faza rekonesansu dotyczy całego systemu, a nie tylko funkcji związanych bezpośrednio ze sztuczną inteligencją.
Następnie przechodzimy do testów manualnych, podczas których koncentrujemy się na identyfikacji podatności, szczególnie tych, które mogą prowadzić do realizacji kluczowych zagrożeń zidentyfikowanych podczas sesji modelowania zagrożeń. Warto zaznaczyć, że nasze testy wykraczają poza komponenty związane z AI i obejmują kompleksową ocenę bezpieczeństwa całego systemu.
Skontaktuj się z naszym ekspertem!

Na zakończenie przeprowadzamy testy automatyczne z wykorzystaniem wybranych narzędzi zgodnych z wytycznymi OWASP GenAI Red Teaming Guide. Narzędzia dobierane są w zależności od kontekstu systemu biznesowego, tak aby jak najlepiej objąć całą powierzchnię potencjalnego ataku. Wygenerowane wyniki są następnie analizowane pod kątem tego, które ładunki (payloady) wywołały nieoczekiwane lub niekontrolowane zachowanie modelu. Wykryte anomalie są dodatkowo ręcznie weryfikowane i analizowane, aby zmaksymalizować skuteczność narzędzi testujących. Do oceny ryzyka zidentyfikowanych problemów bezpieczeństwa wykorzystujemy standard OWASP AIVSS.
Faza III – raportowanie
Po zakończeniu testów przekazujemy raport zawierający zidentyfikowane podatności wraz z rekomendacjami, w tym przykładami typu proof-of-concept, strategiami łagodzenia ryzyka oraz dodatkowymi zaleceniami. Raport zawiera również wyniki sesji modelowania zagrożeń, wskazując kluczowe obszary wymagające szczególnej uwagi w celu pełnego zabezpieczenia systemu przed potencjalnymi atakami.
Uzyskaj wycenę swojego projektu

Umów się na rozmowę lub wypełnij nasz formularz kontaktowy, aby uzyskać wycenę usługi AI Red Teaming. Każda organizacja jest inna, dlatego skontaktujemy się z Tobą, aby omówić szczegółowo Twoje potrzeby oraz poznać szerszy kontekst testów bezpieczeństwa.
Pamiętaj, że jeśli Twój system mówi, generuje, rekomenduje lub interpretuje, to potrzebuje on testów AI & LLM Red Teaming.