
AI Red Teaming

AI Red Teaming or LLM Red Teaming is a security testing process that simulates real-world attacks on AI-driven systems, especially those using Large Language Models (LLMs), to identify their vulnerabilities, abuse potential, and business risks.
Unlike traditional pentesting, AI & LLM Red Teaming targets how AI models behave, respond to prompts, and interact with users. This includes testing for prompt injection, model manipulation, data leakage, and misuse in real-world contexts.
Artificial intelligence’s expanding role and rising security concerns
LLMs and other generative AI systems have permanently transformed the technology landscape. As they continue to grow and evolve, new mechanisms such as Retrieval-Augmented Generation (RAG) and Model Context Protocol (MCP) are being introduced to further enhance LLMs’ capabilities and extend their functionality beyond previously known limitations.
The increasing complexity of such systems significantly expands the potential attack surface. More companies are concerned about AI threats. According to The Arctic Wolf State of Cybersecurity 2025 Trends Report, 29% of security leaders indicated AI, LLMs, and privacy issues as their main cybersecurity concern, making it their top area of focus.

The HiddenLayer 2025 AI Threat Landscape Report reveals that 89% of IT leaders consider most or all AI models in production to be critical to their organization’s success. Despite this, many continue to operate without comprehensive safeguards – only one-third (32%) have implemented technological solutions to address AI-related threats.
Moreover, nearly half (45%) of organizations did not report an AI-related security incident due to concerns over reputational damage.
Connect with our AI Expert!

There should be a continuous need to strengthen the security posture of the solutions built upon AI, as they are becoming critical assets from an organizational perspective.
AI & LLM (GenAI) security testing
According to the OWASP GenAI Red Teaming Guide, GenAI Red Teaming is the structured practice of emulating adversarial behaviors targeting Generative AI systems, such as Large Language Models (LLMs), with the aim of discovering weaknesses that affect their security, safety, and trust. By adopting an attacker’s mindset, we can expose potential issues before they lead to serious consequences.
Complementing traditional security testing, AI / LLM Red Teaming examines whether the behavior or output of the generative model can lead to unintended consequences, including the generation of harmful, unethical, or inappropriate content. Furthermore, Red Teaming exercises help assess how well LLM safety measures, such as guardrails, content filters, and other mitigation techniques, perform in real-world scenarios to prevent AI misuse.

All of this makes AI / LLM Red Teaming an invaluable tool for evaluating the security of generative AI systems.
Why testing AI is different?
Traditional security and testing methodologies are no longer sufficient in the context of AI-driven solutions. Unlike conventional software, Generative AI systems introduce new classes of AI-based risks that are dynamic, non-deterministic, and often impossible to uncover using standard pentesting techniques.
Testing has to change, it needs to reflect how GenAI really behaves and the kinds of risks it brings.
Our testing approach
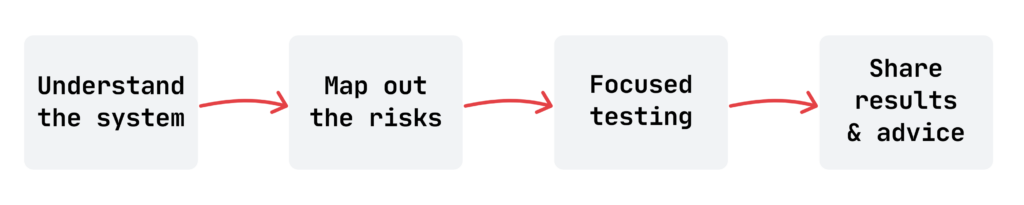
As part of our testing process, we take a comprehensive approach to assessing the security of AI-driven systems. To begin with, we analyze and review the system’s architecture to fully understand its components, data flows, and critical assets. Such analysis allows us to tailor the pentesting assessment to the specific system’s unique characteristics.
Then, we conduct threat modeling exercises, either in collaboration with the Client or internally (however, collaboration is definitely preferred!). In this phase, we define potential threats and risks specific to the system under review, considering its architecture, functionality, and use cases. We then assess their potential impact and evaluate possible mitigation strategies to reduce their likelihood or severity.
Next, we perform both automated and manual tests, with a strong focus on the system’s business purpose to ensure we cover the whole potential attack surface. During red teaming, we leverage information gathered during the threat modeling phase to guide and prioritize our testing efforts, ensuring they align with the identified risks.
Finally, we deliver a detailed report of the identified security vulnerabilities and recommendations. That includes also the results of the threat modeling phase, helping the Client further strengthen the overall security posture of their system.

Throughout the process, we rely on the latest security standards and best practices for AI / ML / LLM systems, such as OWASP TOP 10 Large Language Model Applications, OWASP GenAI Red Teaming Guide, MITRE ATLAS or Google’s Secure AI Framework (SAIF).
Phase I – Threat Modeling
If you’re already familiar with our Threat Modelling service, you know what to expect – a high-quality, tailored approach adapted to the specific system and business context. When it comes to Threat Modelling for AI systems, we focus on AI-specific risks, such as unintended output generation, prompt injection vulnerabilities, data leakage, or unpredictable model behavior.
We typically conduct the Threat Modelling process in collaboration with the Client, which helps us gain a deep understanding of the system’s architecture, input/output flow, and real-world use cases. When needed, we also perform the analysis internally, involving Securing’s team of experts experienced in testing and securing AI-based systems.
Our goal is to identify potential attack vectors, risks, and threats, consequently evaluating the security of the AI system’s architecture.

Phase II – Security Testing

At the beginning of the security testing process, we familiarize ourselves with the AI system by conducting reconnaissance. That includes examining how general communication with the model works in practice, how the model responds to basic prompts, and what data is sent to the model (not only at the prompt level but also via the API). We also verify what features the application offers and whether the model behaves as expected. While many of these actions focus on the AI model itself, the reconnaissance phase applies to the entire system – not just the AI-related functions.
Next, we move on to manual testing, during which we focus on identifying vulnerabilities – particularly those that could result in the realization of key threats identified during the Threat Modelling session. It’s important to note that our tests go beyond AI components and include a full evaluation of the system’s overall security.
Connect with our Red Team Expert!

Finally, we perform automated tests using selected tools compliant with the OWASP GenAI Red Teaming Guide. The tools are chosen based on the system’s business context to cover the attack surface best. The generated output is then reviewed to determine which payloads triggered unexpected or uncontrolled behavior from the model. Detected anomalies are further manually examined and validated to maximize the effectiveness of automated testing tools. To assess the risk of identified security issues, we use OWASP AIVSS standard.
Phase III – Reporting
After completing the tests, we report the identified vulnerabilities along with recommendations, including proof-of-concept examples, mitigation strategies, and other recommendations. Additionally, the report contains the results of the Threat Modelling session, highlighting the key areas that require focus to fully secure the system against potential adversaries.
Get a quote for your project

Book a call or fill out our contact form to get a quote for AI Red Teaming. Every organization is different – we’ll get in touch with you to determine the specifics of your needs and the broader context of security testing.
And remember, if your system talks, generates, recommends, or interprets, it needs AI & LLM Red Teaming.

