
Exploring 25K AWS S3 buckets
Problems with AWS S3 buckets’ permissions are as old as the service itself. I think that 2 the most known researches about this issue were performed by Skyhigh pointing that 7% of all S3 buckets are open and by Rapid7 pointing that even 17% are open. Today we are in 2018 and I’ve decided to check what is the current status of the problem. Additionally, I want to present my techniques of performing such research — if I missed any clever one, please let me know in the comments.




Exploring 25K AWS S3 buckets
Problems with AWS S3 buckets’ permissions are as old as the service itself. I think that 2 the most known researches about this issue were performed by Skyhigh pointing that 7% of all S3 buckets are open and by Rapid7 pointing that even 17% are open. Today we are in 2018 and I’ve decided to check what is the current status of the problem. Additionally, I want to present my techniques of performing such research — if I missed any clever one, please let me know in the comments.
Let’s start with some theory
All the AWS S3 buckets can be accessible using the following URLs:
https://[bucket_name].s3.amazonaws.com/
https://[aws_endpoint].amazonaws.com/[bucket_name]/or using AWS CLI:
$ aws s3 ls --region [region_name] s3://[bucket_name]
Not often people point to the need of using a region parameter. However, some buckets don’t work without specifying a region. I don’t see a pattern when it works and when it doesn’t so a good practice is to always add this parameter 🙂
So, generally speaking finding a valid bucket equals finding a subdomain of s3.amazonaws.comor [aws_endpoint].amazonaws.com . Below I’m gonna go through 4 methods which may be helpful in this task.
Bruteforcing
Each bucket name has to be unique and can contain only 3 to 63 alphanumeric characters with a few exceptions (can contain ‘-‘ or ‘.’ but it cannot be started or ended with). That being said, we’re weaponized with knowledge enough to find all S3 buckets, but let’s be honest — it would work rather for short names. Nevertheless, people tend to use some patterns in naming, e.g. [company_name]-dev, or [company_name].backups. Once you’re searching for a particular company’s bucket then you can easily automate a process of verifying such well known patterns using tools like LazyS3 or aws-s3-bruteforce. Let’s say we have a company called Rzepsky. A simple command:$ ruby lazys3.rb rzepsky reveals a rzepsky-dev bucket:
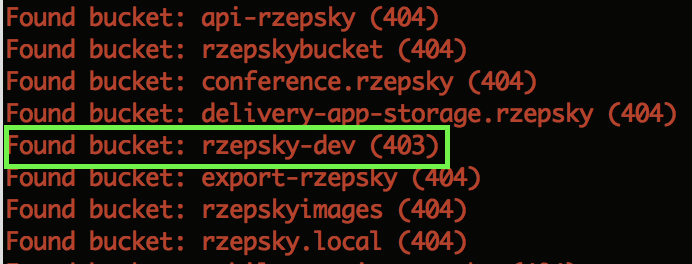
But what if you want to harvest as many buckets as possible without any specific name to start with? Keep reading this post 😉
Wayback Machine
Have you ever heard about the Wayback Machine? Quoting Wikipedia:
The Wayback Machine is a digital archive of the World Wide Web and other information on the Internet created by the Internet Archive.
Some resources in this digital archive are stored on Amazon infrastructure. That being said, if the Wayback Machine has indexed just one photo on a S3 bucket, we can retrieve this information and check if this bucket contains any public resources. Even when the indexed photo is already removed (or access to it is denied) you still have the name of the bucket, what gives a hope for finding interesting files inside. For asking the Wayback Machine’s API, you can use a Metasploit module called enum_wayback:
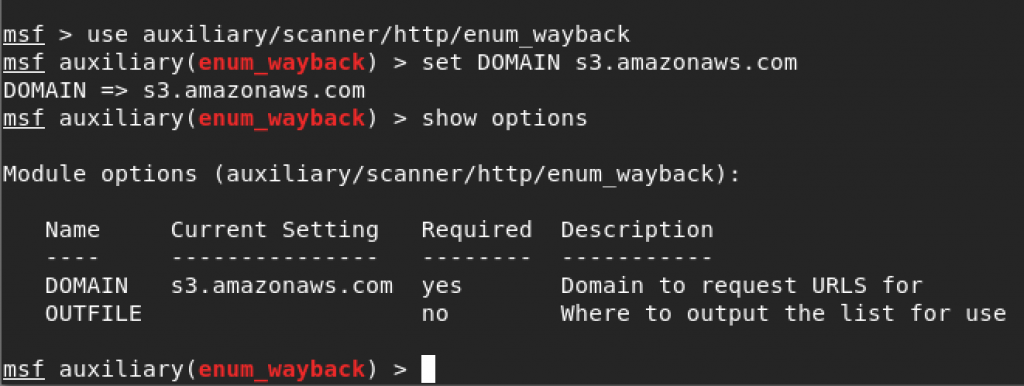
As you may remember from the beginning of this post you can refer to bucket’s content also using a URL with region specification. So, to get even better results, we can check subdomains of every possible Amazon S3 endpoint, by a simple bash one-liner:
$ while read -r region; do msfconsole -x "use \ auxiliary/scanner/http/enum_wayback; set DOMAIN $region;\
set OUTFILE $region.txt; run; exit"; done < s3_regions.txtVery often the Wayback Machine gives you back few thousands of pictures placed in just one bucket. So, you have to do some operations to pull out only valid and unique bucket names. Programs like cut and awk are great friends here.
The Wayback Machine gave me 23498 potential buckets in a form of 398,7 MB txt files. 4863 of those buckets were publicly open.
Querying 3rd parties
Another technique which I’d like to introduce is querying 3rd parties, like Google, Bing, VirusTotal etc. There are many tools which can automate the process of harvesting interesting information from external services. One of them is the Sublist3r:
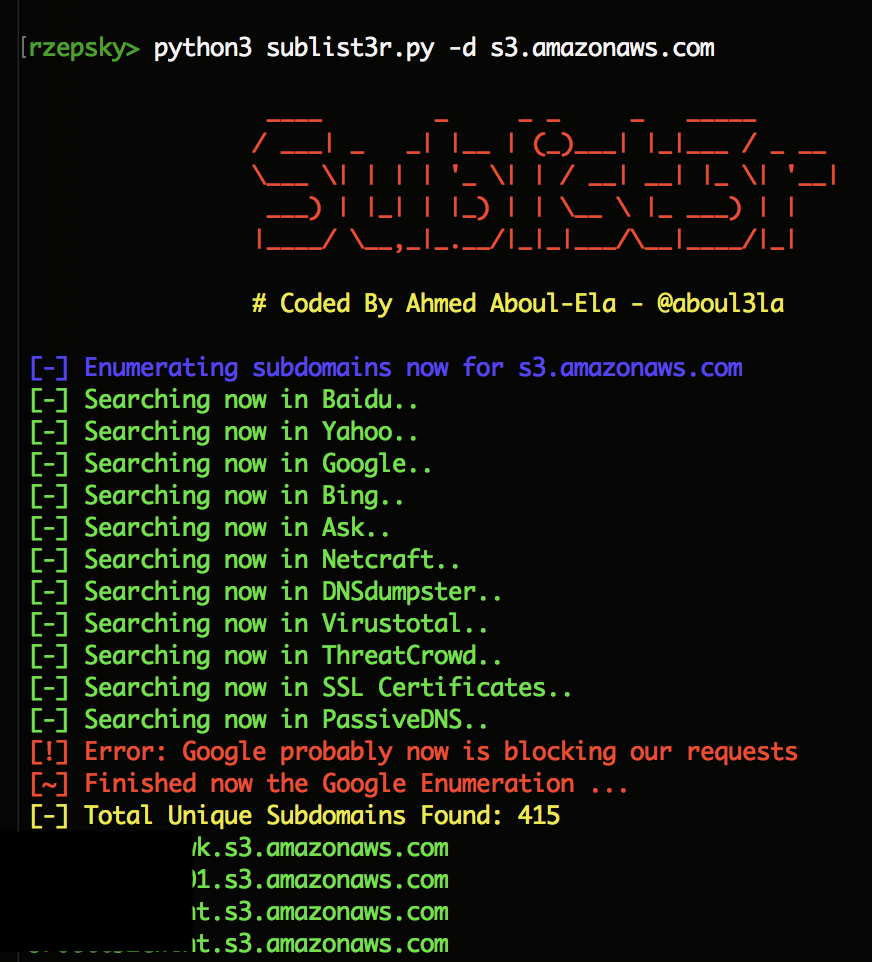
Again, we should search subdomains of each region and then pull out only unique bucket names. A quick bash one-liner:
$ while read -r region; do python3 sublist3r.py -d $region \
> $region.txt; done < s3_regions.txtgives as the result 756 from which… only 1 bucket was collectable. Beer for the administrators!

Searching in certificate transparency logs
The last technique which I would like to present you is searching bucket names by watching certificate transparency logs. If you aren’t familiar with certificate transparency, I recommend you watching this presentation. Basically, every issued TLS certificate is logged and all those logs are publicly accessible. The main goal of this idea is to verify if any certificate is not mistakenly or maliciously used. However, the idea of public logs reveals all domains, including… yeah, S3 buckets too. Good news is that there’s already available tool which is doing a search for you — the bucket-stream. Even better news is that this tool is also verifying permissions to the bucket it found. So, let’s give it a shot:
$ python3 bucket-stream.py --threads 100 --logAfter checking 571134 possibilities the bucket-scanner gave me back 398 valid buckets. 377 of them were open.
Verifying the bucket’s content
Alright, we found thousands of bucket names and what next? Well, you can for example check if any of those buckets allow for public or for Any authenticated AWS user (which is basically the same as public) access. For that purpose you can use my script BucketScanner — it simply lists all accessible files and also verifies the WRITE permissions to a bucket. However, for the purpose of this research I modified a bucket_reader method in the following way:
def bucket_reader(bucket_name):
region = get_region(bucket_name)
if region == 'None':
pass
else:
bucket = get_bucket(bucket_name)
results = ""
try:
for s3_object in bucket.objects.all():
if s3_object.key:
print "{0} is collectable".format(bucket_name)
results = "{0}\n".format(bucket_name)
append_output(results)
breakWhile it isn’t the most elegant way it does its job — if just one file was collectable in the bucket, then my modified scanner reports this bucket as collectable.
The risks
Among the publicly accessible files you can find really interesting ones. But leaking of sensitive data is not the only risk.
Some buckets are publicly writable. For sure an attacker can use such bucket as a malware distribution point. It is even more scary if you’re using such bucket for distributing a legit software among your employees — just imagine such scenario: you’re guiding all newcomers to install a software from the company’s bucket and this software is already overwritten by an attacker with infected installer. The other variation of this scenario would be trolling S3 researchers — e.g. by uploading infected file with a tempting name, like “Salary report — 2017.pdf” (of course all responsible researchers always download untrusted files to sandboxed environment, right?)
Another risk with publicly writable buckets is… that you can lose all your data. Even if you don’t have DELETE permissions to bucket’s objects, but just a WRITE permission you can still overwrite any file. That being said, if you overwrite any file with empty file it means that this file is no longer available for anyone. Let’s take a look at this example:
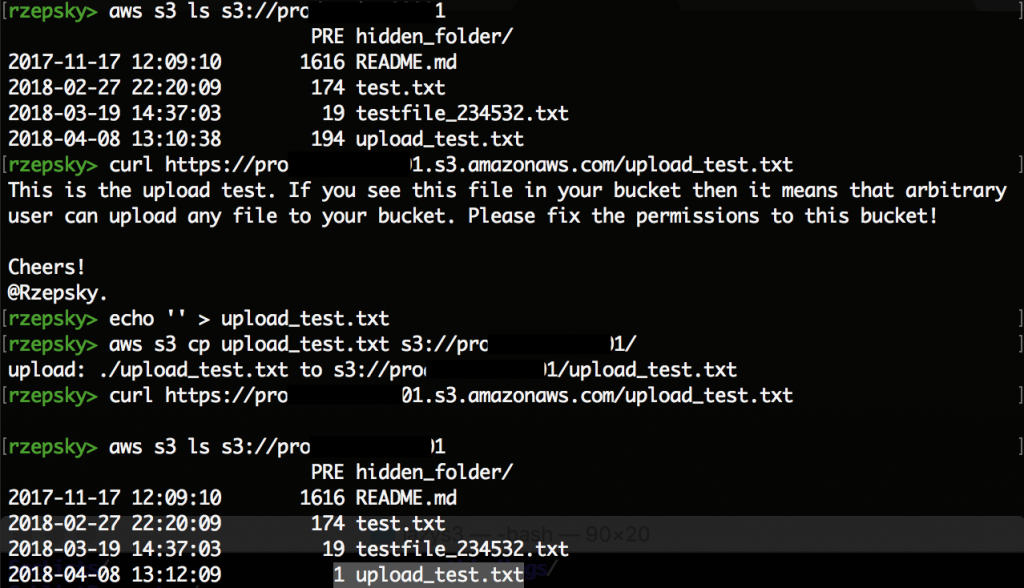
The only mechanism which can save your data in such scenario is enabling a versioning. However, this mechanism can be expensive (it doubles the size of used space in your bucket) and not many people decide to use it.
I’ve also heard an argument:
Oh, c’mon it’s just a bucket for testing purpose.
Well, if your “test” bucket becomes a storage for illegal content, then… sorry dude but it’s your credit card pinned to this account.
Any brighter future?
The problem with S3 buckets permissions still exists and I don’t expect a spectacular change in the nearest future. IMHO people give the public access, because it always works — you don’t have to worry about specifying permissions when a S3 service cooperates with other services. The other reason can be a simple mistake in configuring permissions (e.g. putting a “*” character in a wrong place in a bucket policy) or not understanding predefined groups (e.g. a group “Any authenticated AWS account” can be still set up via AWS CLI).
Another problem is how to report such problems? There’s no email pinned to the bucket so you can never be sure who should you contact with. The names of buckets may indicate they belong to company X, but remember that anyone can loosely name it. So watch out for trollers!
Summary
For 24652 scanned buckets I was able to collect files from 5241 buckets (21%) and to upload arbitrary files to 1365 buckets (6%). Based on the results I can say with no doubt that the problem still exist. While some buckets are intentionally opened (e.g. serves some pictures, company brochures etc.), neither of them should be publicly writable. I’m pretty sure there are other cool methods of finding even more buckets, so the only reasonable countermeasure seems to be… setting right permissions to your bucket😃

Please find also my Seven-Step Guide to SecuRing your AWS Kingdom.