
What can you find in 57K AWS S3 buckets? 2021 update
Cloud infrastructure is becoming a standard, but correct access settings still do not seem so obvious. See how we managed to get to some really interesting resources.




What can you find in 57K AWS S3 buckets? 2021 update
Almost 3 years have passed since my friend – Paweł Rzepa – did a research about open S3 buckets. The situation did not look good then, but maybe the topic of cloud security was not as widely publicized as it is today. However, with each subsequent AWS penetration test and assessment in my work, I get surprised how often we are finding open buckets with sensitive data.
So it turns out that the topic is not as obvious as it seems. Therefore, I decided to revise this research and confront what it looks like in 2021. The results did not disappoint me so here is my attempt.
Revision of the basics:
What is an AWS bucket?
AWS S3 Bucket is (according to its documentation) “Object storage built to store and retrieve any amount of data from anywhere” – it could be used as cloud storage (like Google Drive), static content storage served by CDN or even as a static website!
How to use knowledge about buckets?
As you probably know, access to the buckets is possible not only using AWS CLI, SDK or Console, but also using HTTP endpoints – more specifically:
http[s]://[bucket_name].s3.amazonaws.com/
http[s]://s3.amazonaws.com/[bucket_name]
http[s]://s3-[region_name].amazonaws.com/[bucket_name]As mentioned above, S3 Buckets could be also used to host static websites, where I noticed that sometimes the domain name is equal to the bucket name, as presented in Scott Piper flaws.cloud challenge:
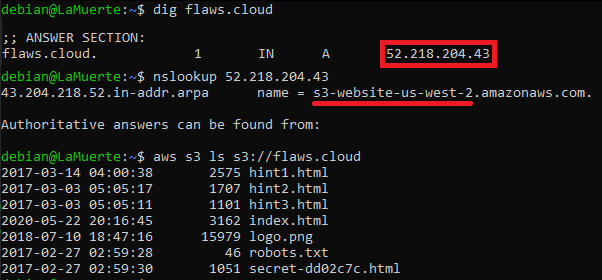
By using these facts, we could apply various techniques and tools to search for S3 buckets.
Method for finding bucket names
So what can we do to find as many bucket names as possible (and be able to scan them)? I did a few things listed below:
- Enumerate Wayback Machine using Metasploit enum_wayback module
- Use discovery (OSINT) tools – Sublist3r and Amass
- Watch certificate transparency logs
- Gather data about companies that use AWS – scan, map, and brute force them*
*Disclaimer – using this method I chose only companies with Bug Bounty programs which allows for actions like that!
Wayback Machine
Wayback Machine is a commonly known digital archive of the World Wide Web. Everything that has been indexed by it, could be then retrieved using a proper API call. If there was a single file on an S3 bucket that was indexed, we can obtain its URL and extract the bucket name. Even if the indexed file is already inaccessible (deleted or set private), we still have the name of the bucket, which could be scanned.
Our goal is to search for different S3 endpoints to gather every possible indexed URL – to do this I used Metasploit module called enum_wayback:
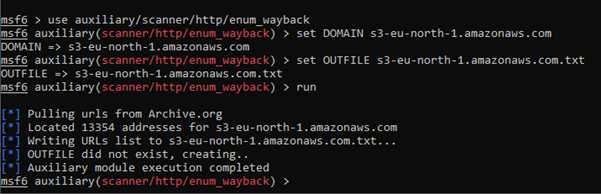
As previously mentioned, it is possible to refer to the bucket’s content using a URL with region specification. By saving every region name to the file and using this simple bash one-liner, we can make our results even more precise:
$ while read -r region; do msfconsole -x "use \
auxiliary/scanner/http/enum_wayback; set DOMAIN $region;\
set OUTFILE $region.txt; run; exit"; done < regions.txtUsing this method, I gathered about 900MB of txt files, but as you probably suspect, there were a lot of useless paths and duplicates of the same names – awk, cut, uniq and sort in this situation were my best friends.
To sum up – I extracted 31177 potential bucket names and 4975 of them were publicly open. Furthermore, I was able to write to 764 of them.
OSINT tools
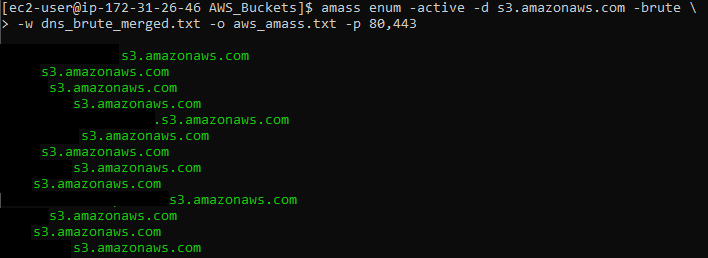
Wayback Machine is not the only service that gathers data like that – there are also search engines (Bing, Yahoo, Google), different APIs (CommonCrawl, ZoomEye, URLScan, VirusTotal) and techniques like reverse DNS sweeping. Doing everything manually would take a lot of time, so I decided to use two tools that harvest data for me – Sublist3r and Amass:
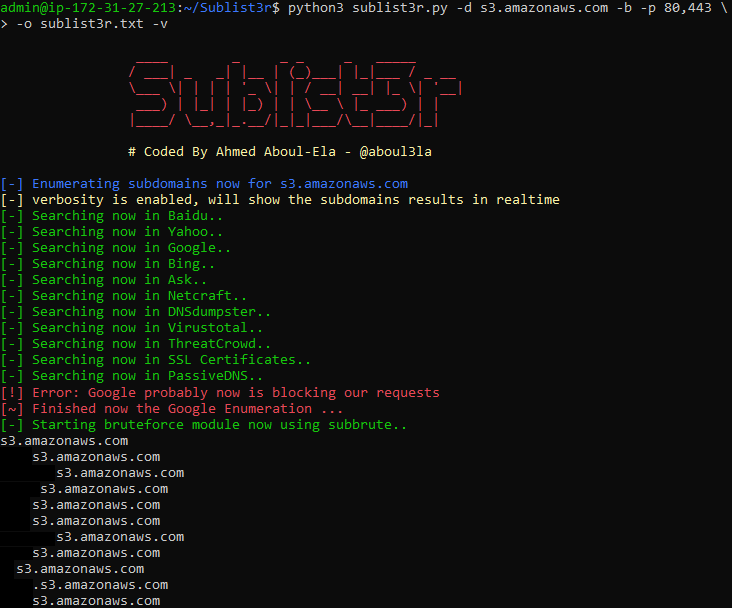
Sublist3r:
And going to the results – Amass gathered a total of unique 29562 bucket names, where I was able to read 4800 of them and write to 1148.
Sublist3r collected a crazy amount of 125525 bucket names! But to our misfortune, 122468 of them did not exist, so we are left with 193 publicly open buckets and 59 writable ones.
Certificate transparency logs
One of the mentioned techniques was listening to certificate transparency logs. Quoting Wikipedia – “Certificate Transparency (CT) is an Internet security standard and open source framework for monitoring and auditing digital certificates.”
As you may know, every issued TLS certificate is logged publicly (to verify if a certificate is properly issued and is not maliciously used). The idea of this is correct, but… it leaks publicly every domain – also the S3 buckets, which is good for us!
Because I’m not the first who figured it out, there’s already an open-source tool called the bucket-stream.
After running it for two days, I gathered 310 bucket names, where only 16 were accessible, and to 4 I was able to write.
And now the fun part: scanning, mapping and bruteforcing
The last method I used and I guess the most interesting one (despite not having the most spectacular results) – gathering data about companies that use AWS services.
By searching through public statistics of AWS usage, as well as HackerOne and BugCrowd scopes – I created a list of companies that allow bug bounty, just to be sure everything I’m doing is legal.
While browsing their BB programs, I created also domain lists basing on their scopes:
Discovery time!
That was not enough – so the first thing I did was to use Amass again, to gather even more subdomains! To do this, I used the following command:
$ amass enum -active \
-d $(sed -z 's/\r\n/,/g;s/,$/\r\n/' bounty_domains/redacted.txt) \
-brute -w dns_brute_merged.txt -o redacted_amass.txt -p 80,443
59358 – this is the number of addresses I gathered from 19 targets.
You are probably thinking now:
“So what? They aren’t S3 buckets or even any AWS service”
And you’re right! And I’m going to describe what I did to search for S3 buckets from this dump, right below 😉
Inspecting found domains
In the next step, I used a tool called Aquatone, which did a lot of work for me – by screenshotting every page and harvesting headers from all of the accessed addresses:
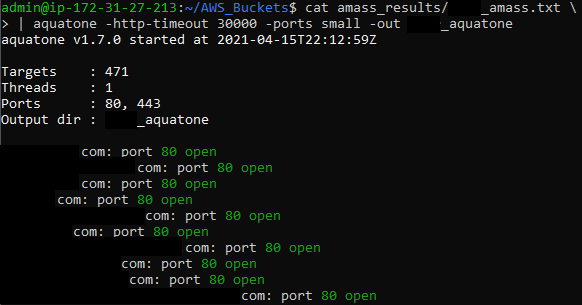
It took some time, but in the end I was left with 2,7GB of output data (mainly screenshots and txt). By searching for a header “server: AmazonS3” I was able to extract 178 addresses.
It turned out that most of them were behind a CDN, probably with access restricted only for CloudFront! 19 of them were correct bucket names, where only 1 was publicly accessible.
Brute-force
The last thing in my prepared arsenal is Brute-forcing bucket names! I used a popular tool named LazyS3 for guessing on the basis of a company name set as an argument:
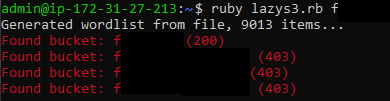
Results? 965 bucket names, where 64 of them were open publicly, and to 25 I uploaded a test file.
An overview of our findings – what are those buckets?
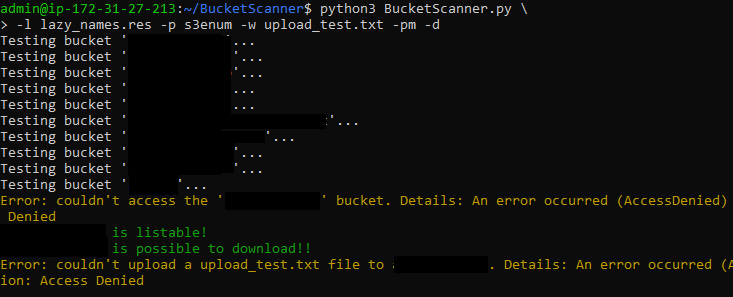
Paweł created a tool named BucketScanner, but I found it lacks a few functionalities and is a little bit outdated, so… I’ve updated it!
First thing – I’ve changed the code to use Python 3.6+ and the newest versions of libraries (boto3, requests).
Furthermore, I wanted to add a passive scanning mode, which Paweł described in his article, as one of the available methods. I’ve added more detailed logging, some colours – and voilà:
Why deal with AWS buckets in the first place?
As I mentioned – it was an interesting thing for me to do. I also had a chance to experiment a bit more with AWS and test my skills.
Furthermore, it is worth mentioning that a lot of people search for “How to make AWS bucket public” – I think Amazon did a good job securing this service, by making it private by default, implementing features blocking public access (which even prevent from making bucket public accidentally) and forcing the user to tick a million checkboxes and to write “confirm” at every step of making a bucket public.
The only thing which could be quite confusing, especially for new users, is mixing IAM Policies with Bucket Policies, Bucket Access Control Lists, and Object Access Control Lists.
But the most important thing is… S3 Buckets are used for various purposes – they can host a website, store logs, databases, backups, datasets… To sum up – a lot of awfully fascinating data!
So what exactly have I found?
I was surprised by what I saw at the beginning (I even jumped up in my chair) and then I even got a little scared. I’ve found a handful of buckets with database dumps (or backups) – this could be a huge client’s data leak! For now, everything is reported and we are waiting for feedback. I have been wondering for a long time whether to share at least a little bit of the secret, but until we get an answer from that company, we remain these good guys as usual; )
Searching through other findings was also fun at times!

Ok, but what could be the consequences?
You are reading about one of them right now, as said above – database leak (or any other sensitive data like backups, logs, reports, private code etc.).
Furthermore, the possibility of writing to the bucket enables multiple malicious options:
- Creating a new webpage/overwriting the existing one with added malicious code, as it happened to Apple once
- Deleting stored data (and probably you forgot to enable MFA Delete to countermeasure this ;)) – and even without DELETE permission, overwriting a file is equivalent to deleting it, if Versioning is disabled.
- Storing malware in your bucket with some tempting name “Annual Finance Summary 2021.pdf” – your business department uses a sandboxed environment when downloading data from your infrastructure?
And remember – that is your bucket – this account is pinned to you or your company, so it is your problem, if there is any unwanted content.
Summary
For a total of 185381 unique bucket names, 57221 were still existing ones – I was able to access 9860 (17,2%) of them, and upload a file to 1965 (3,4%) buckets.
Compared to results obtained 3 years ago (24652 scanned buckets, 5241 – 21% – publicly open and 1365 writable – 6%) we can see some improvement! But the problem still exists and there is still a possibility of hearing about giant leaks like CSC-BHIM or code modification of open-source tools.
How to secure your buckets?
My fairly obvious suggestion is that early prevention is the best option. That’s why at the beginning you should focus on setting efficient bucket permissions for your case. It’s always a good time to look into your setup, especially when it comes to security!
The second piece of advice is to look at your infrastructure from a fresh and broader perspective, for example with the help of professional security audits.
Certainly, with time, I will discuss more topics related to security of the broadly understood cloud. If you want to stay up-to-date with my discoveries you can find me on Linkedin or just give a quick follow on Twitter!