
What is going on with OAuth 2.0? And why you should not use it for authentication.
A few weeks ago I was planning to write an article explaining why it is not a good idea to use OAuth for authentication (as Auth in OAuth stands for authorization and not authentication for a reason), but the draft of OAuth 2.0 Security Best Current Practice has been published and an interesting discussion appeared on Twitter.




What is going on with OAuth 2.0? And why you should not use it for authentication.
A few weeks ago I was planning to write an article explaining why it is not a good idea to use OAuth for authentication (as Auth in OAuth stands for authorization and not authentication for a reason), but the draft of OAuth 2.0 Security Best Current Practice has been published and an interesting discussion appeared on Twitter.
Given this, I decided not only to explain why you must not use OAuth 2.0 for authentication on example of quite twisted vulnerability, but also I tried to review the current best practices for OAuth 2.0, argue whether we should or should not deprecate the implicit grant type and explain the idea of PKCE, which I found a great example of best practices.

Quick introduction to OAuth 2.0
Let’s introduce the OAuth 2.0 and its grant types. If you are familiar with that, you can jump to the next section.
OAuth stands for Open Authorization Framework and is the industry-standard delegation protocol for authorization. OAuth 2.0 is widely used by applications (e.g. SaaS platforms) to access your data that is already on the Internet. That includes for example your contacts list on Google, your friends list on Facebook, etc. If you were ever asked by web or mobile application to give permissions to access your personal data, you have probably used OAuth 2.0.
OAuth includes 4 actors in the process of access delegation:
- resource owner (basically a user who has some private resources like email, photos, etc.),
- client (usually an application that wants to access these resources),
- authorization server (who asks the resource owner for access to the resources on behalf of the client),
- resource server (who stores user’s private resources and shares them with authorized clients).
In some cases the same application acts as both, the authorization server and resource server (e.g. Facebook).
There are four flows (called grant types) to obtain the resource owner’s permission (technically called access token): authorization code, implicit, resource owner password credentials and client credentials.
I am going to skip last two, because resource owner password credentials flow is used for trusted clients that require resource owners to provide their credentials and client credentials is used to access resources owned by the client itself. These two flows are usually used when the client and authorization server are part of the same system. Otherwise, you should not use it (both as resource owner and developer of client application) because resource owner’s credentials to authorization server are revealed to third party!
The authorization code and implicit grant types are more interesting as they are used by public clients and users give their permission to third party applications. That introduces higher risk! The main difference is that implicit grant type returns the access token right away in the response to the authorization request. The authorization code grant type returns the code instead and client has to send the second request to exchange the code for access token.
The implicit grant type looks simpler (less requests), but this slight difference has also some security implications. So, if you wonder why the implicit type was included in OAuth 2.0, the explanation is simple: Same Origin Policy. Back then, frontend applications were not allowed to send requests to different hosts to get the access token using code. Today we have CORS (Cross-Origin Resource Sharing).
Why did the discussion start?
It started after the draft of OAuth 2.0 Security Best Current Practice was published. The authors proposed that clients should not use implicit type (“or any other response type causing the authorization server to issue an access token in the authorization response”) and use authorization code type instead.
The justification for that statement was the existence of multiple threats, like Insufficient Redirect URI Validation, Credential Leakage via Referrer Headers,
Attacks through the Browser History or Access Token Injection and “no viable mechanism to cryptographically bind access tokens issued in the authorization response to a certain client”.
To put it in simple words, there are two main threats for implicit type:
- the leakage of access token transmitted in the URL (also as fragment),
- the injection of access token, undetectable by the client.
Token leakage
The leakage threat is covered in RFCs related to OAuth. For example, the open redirect vulnerability was mentioned many times, even in the first OAuth 2.0 RFC [6749]. So basically, when you follow the standard, you significantly reduce the risk. Of course, the truth is that if something is prohibited in the standard it does not mean it will not happen and we should strive to create recommendations as secure as possible, minimizing the risk. Actually, that was the motivation of the published draft. On the other hand, if you do not follow the standard properly, you are always at higher risk.
Futhermore, the history shows that bugs in software beyond the reach of OAuth server’s and client’s developers (like the one in Chromium) introduce new vectors for token leakage such as beforementioned leakage via referer header or browser history. That is another motivation to adjust standards to the current situation.
Token injection
The injection threat comes from the fact that client cannot assume that only the resource owner can present it with a valid access token for the resource. Therefore, an adversary can easily inject the leaked or stolen access token (and impersonate the resource owner) when client accepts access tokens from sources other than the return call from the token endpoint. That happens when client uses an implicit flow.
This threat is also related to the fact that OAuth framework must not be used for authentication. The OAuth 2.0 RFC stays as follows:
Authenticating resource owners to clients is out of scope for this specification. Any specification that uses the authorization process as a form of delegated end-user authentication to the client (e.g., third-party sign-in service) MUST NOT use the implicit flow without additional security mechanisms that would enable the client to determine if the access token was issued for its use (e.g., audience- restricting the access token).
The assumption that possesion of a valid access token is enough to prove that a user is authenticated is true only in some cases (when the access token was freshly minted). Indeed, there are other ways to obtain a valid access tokens than authenticating resource owner. For example, using the refresh token. Furthermore, in some cases access grants can occur without the user having to authenticate at all. The anti-pattern of using accessing of a protected API as proof of authentication has been explained here in details.
Using OAuth 2.0 for authentication is really, really a bad idea…
Problems arising from the use of OAuth 2.0 for authentication does not refer only to the implicit grant type, but also other types, including authorization code type.
Lately, I have found an interesting vulnerability in Single Sign-On (SSO) authentication mechanism based on OAuth 2.0. It allowed to log in using accounts from Active Directory.
However, a few of client applications integrated with this mechanism allowed users to log in using Google accounts. Therefore, when user was redirected to SSO from one of these clients, the button to log in with Google account was added on the login page. On the other hand, when user was redirected from another client, the button did not show up.
The clients that accepted Google account either verified whether the logged in e-mail address is accepted (there was a list of accepted Google e-mail addresses) or simply allowed anyone (any Google e-mail address) to have a valid account.
Unfortunately, the other group of clients were not aware of the fact that users can log in to SSO also with Google accounts and additionaly, they did not verify whether the authorization code, that was returned to them with redirection, came from the login process initiated by them. They just used the code to get the access token.
Summing up, the attacker could start the login process for the client that accepted Google accounts, then log in to SSO using any Google account, switch the context of login process to other client that accepted users only from Active Directory and provide it the valid code from SSO. The attacked application generated valid token from the code and let the attacker in.
The result
The above threats convinced authors of the draft to propose a big change in OAuth 2.0 to remove the implicit grant type.
However, it is important to mention that this recommendation does not have to apply to all existing implicit flows, but the OAuth’s only. For example, the OpenID Connect (that should be used for authentication) built on top of OAuth 2.0 also uses implicit type and solves the problem of token injection by introduction the ID token data structure.
The ID Token is a security token that contains Claims about the Authentication of an End-User by an Authorization Server when using a Client, and potentially other requested Claims. The ID Token is represented as a JSON Web Token (JWT).
However, it can be still vulnerable to the leakage attacks and the general advise is not to put access tokens (which have long expiry time) in any part of URLs.
The authorization code for the win (with PKCE)!
The authors of the draft proposed the authorization code type together with the Proof Key for Code Exchange (PKCE) as a mitigation for the implict type threats.
As mentioned before, the primary difference between implicit type and authorization code type is that in the second one the authorization server, upon authenticating resource owner, returns the code to the client. In order to get the access token, the client sends the POST request with the code to the token endpoint thanks to Cross-Origin Resource Sharing (CORS). The response contains the access token.
As the access token is no longer present in the URL, authorization code type is not vulnerable to access token leakage. However, instead of access token, the code is returned in redirected response. That brings back the possible leakage attack on the code parameter (e.g. the open redirect vulnerability would allow to steal the code).
Here comes the PKCE, based on the challenge-verifier scheme. The flow is following:
- Client creates a code challenge (type of challenge function is selected by the client, e.g. the hash of some unique secret) and sends it in the authorization request.
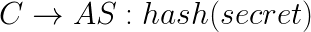
- Authorization server authenticates the resource owner and returns the code.
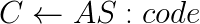
- In order to get the access token client must send the code and prove that he initiated the flow. Therefore he sends the code verifier (e.g. unique secret from the first step) together with the code.
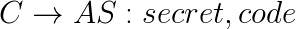
- Authorization server verifies whether the hash of code verifier matches the code challenge and returns the access token.
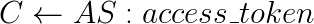
The security introduced by the PKCE comes from the fact that no one, but the legitimate client knows the code verifier. PKCE gives sufficient protection against code leakage (e.g. via open redirection) as the attacker does not have the code verifier.
Besides PKCE, the code should be one time use and have very short expiry time (unlike the access token). That protects the leaked code from being used some time after its creation (minimizes the duration when code is usable).
In my opinion, switching to authorization code type, together with short-lived codes and recommended PKCE, is a good idea as it removes the risk of access token leakage via URL and open redirection. However, I am not yet convinced to stop using implicit type at all, because some of the threats apply also for authorization code type (e.g. code leakage) and there are more important and common threats that are independent from the flow type (e.g. access token storage).
Anyway, the discussion is still on, some hybrid approaches are proposed (e.g. similar to the ID token from OCID) and workshops are planned so I am looking forward for the final version of “OAuth 2.0 Security Best Current Practice”.
Other good tips and considerations for OAuth
During the discussion on Twitter some other threats were mentioned and ideas proposed.
The threat worth mentioning, which is actually indepentent form the grant type is the Cross Site Request Forgery (CSRF). If you do not protect your OAuth implementation from CSRF, the attacker can return fake data from API to your users. It is important to secure OAuth against CSRF attacks with the state parameter. It should be a pseudo random number generated by the client and verified upon reception of the response from the authorization server, which must reply it unmodified.
Another proposed idea was to keep the expiry time for tokens as short as possible or even consider one time use access tokens. I am not a fan of such solution as it is actually against the design of OAuth delegation protocol. Besides, it could drastically decrease UX, when the Single Page Application (SPA) would have to get new access token upon each API call. I would agree on such restrictions for the authorization code instead.
The biggest threat in my opinion is the secure storage of access token. As Single Page Applications (SPA) uses JavaScript to manage the page and retrievie data from API it cannot store the token in HttpOnly+Secure cookies. Instead sessionStorage or localStorage is used, which is accessible to an attacker who finds Cross-Site Scripting (XSS) vulnerability. The first, simple (or is it? ;)) and powerful protection against XSS that comes to my mind is Content Security Policy (CSP).
Unfortunately, as Jim mentions there are many problems with CSP, but I guess it is still worth a try.
However, as CSP prevents a lot of XSS attacks and this is one of the biggest security issues in the Web nowadays, it’s worth it.
— Manfred Steyer (@ManfredSteyer) November 20, 2018
There is also a bunch of other protections against XSS, like the proper encoding on the first line, the X-XSS-Protection header, etc. so, in theory, XSS should be dead.
Conclusions and next steps
The OAuth 2.0 is a framework that you will meet for sure if you have not already. It is important to follow the status of the draft of OAuth 2.0 Security Best Current Practice. But for now, if you are implementing OAuth 2.0 my recommendations are as follows:
- do not use OAuth 2.0 itself for authentication (use OpenID Connect instead),
- use state parameter to prevent CSRF attacks,
- switch to authorization code type from of implicit type and use PKCE,
- implement short-lived and one-time use authorization codes,
- return the access token in the body of HTTP response to POST request using CORS,
- defend your frontend applications from XSS attacks that could steal tokens from localStorage,
- watch out for the open redirection vulnerabilities.
If you are interested in the topic and have some ideas/thoughts/comment you should join the discussion and send me a tweet (@drdr_zz) with #oauth2 hashtag.
You can also join the workshops on this subject, so for example, if you are near Stuttgart in March 2019 you can join 4th OAuth Security Workshop 2019 (OSW 2019).
Thanks to Wojciech Dworakowski.
Head of Blockchain Security