
Storing secrets in web applications using vaults
There is no one-size-fits-all solution when it comes to storing secrets in web applications. Here, you will learn about the useful features of vaults and best practices for keeping your secrets safe.




Storing secrets in web applications using vaults
Modern web applications are becoming increasingly complex. Not only do they rely on external providers, but there is also a visible architectural shift in the way applications are built. Integrations with third-party services often require a web application to prove its identity, which inherently amplifies the problem of secrets management. On the other hand, splitting a once monolithic system into a multitude of microservices causes secrets to be scattered in multiple places. Rotating secrets becomes a complex task. All of this contributes to a growing lack of control over the secrets living in our environments. Without a clear view, the likelihood of secrets being exposed increases. Centralization seems to be the answer. It promises to bring order, flexibility, and a plethora of benefits from having all the jewels in one place.
In this article, we are about to explore:
- Different approaches to storing secrets in web applications and their associated risks.
- Current best practices for managing secrets from an organization-wide perspective.
- Centralized secrets management solutions, commonly referred to as vaults.
Pitfalls of storing secrets in the most common locations
A pair of username and password, an API key, or a TLS client certificate – these are all examples of secrets. In this section, I will look at common ways of storing secrets that we encounter when providing security assessment services to our clients. In the meantime, we will put on our black hats and think about how we can leverage a particular way of storing a secret to our advantage.
Storing secrets directly in source code
Simplicity is a desirable aspect when it comes to security. Unfortunately, while putting your secret directly in the source code is simple, easy for anyone to understand, and gets the job done, it is a big no-go from a security standpoint.
First, if there is a secret in your source code, it probably exists in your version control system (VCS) as well. Major providers like GitHub constantly scan hosted repositories for secrets. But so do attackers. Integrate a codebase scanning process into the CI/CD pipeline to cut concerns about who will discover the secret first. If the secret is detected before it is published to the VCS, the uncertainty disappears. Second, it can be dangerous to rely solely on the fact that a repository is marked private. The repository may one day become public, with all the secrets buried in the change history. In short, no repository should hold secrets as this fact renders it a high-value target for attackers. Finally, a code repository may be hosted on an internal network. Even so, code can be unintentionally exposed when a deployment is accompanied by its .git or .svn directories. Not to mention internal repositories that do not require authentication and are not firewalled. Knowing their URL and just one compromised workstation in the organization is all that stands between your codebase and some shady discussion forum.
Leaving aside the development phase, let’s examine an application that has already been deployed. Its code can live either on the client side or on the server side.
In a scenario where a secret is put into a JavaScript file, all that is required to expose this secret is a user spawning web browser’s developer tools and glancing through the source code. If you think no such thing would ever affect a major website, inspect the source code of weather.com’s main page from a while back (hint: search for SECRET_KEY).
What about code that runs on the server side? Surely, this is a more secure execution environment, isn’t it? Let’s consider an attacker who can read files from the application’s underlying file system. There are many types of vulnerabilities that can provide this capability, including directory traversal, XML external entity (XXE), server-side request forgery (SSRF), SQL injection, and local file inclusion (LFI).
Typically, the application runs in the context of a dedicated user, such as www-data. In this case, the application relies on operating system-level permissions to access its resources. Assuming it is deployed as a set of scripts that need to be interpreted (think Python, for example), they must remain readable. No interpreter will run code it cannot read. In fact, an attacker exploiting a vulnerability forces the application to read files on their behalf. It effectively grants them permissions of the application, and results in access to secrets stored inside these files. There is one more step needed for this attack to succeed: an attacker must guess the exact location and name of the source file. Hackers have been historically highly effective at content discovery. With the advent of high-quality data sets, such as those provided by Assetnote, and blazingly fast tools (like ffuf and ferox-buster), the odds are still in their favor.
Alternatively, the application may be deployed as a binary. While it is possible to run a binary with the execute permission exclusively (at least in Unix-like OS), I have not seen many binaries in the wild with read permissions deliberately stripped off. As a result, the attacker who gets their hands on the binary will be able to extract the secret from it without much effort.
Storing secrets in a configuration file
Configuration files do a good job of separating configuration data from program logic. When used, transferring deployments between different environments is a breeze. An application can use a different database in development and test systems and have other options conveniently customized. At first glance, a configuration file may seem like an attractive place to keep secrets.
How does it compare to storing a secret in source code, in terms of security? There is hardly any difference, and the reason is that configuration files can also be accidentally uploaded to a code repository. Of course, there are mechanisms like the .gitignore file that should prevent this. In reality, there are too many code changes made by too many people, not to eventually leak a secret through this channel. Also, recall the attacker with the ability to read files due to a vulnerability in an application – they can access a configuration file just as easily as a source file.
Storing secrets in environment variables
Environment (env) variables are key-value pairs that are part of an environment in which a process runs. By default, when the process is spawned, environment variables that exist in its parent execution environment are replicated. They end up in the uppermost region of process memory, just above the stack. The provisioning of env variables is typically done by an operating system or a microservice. This means that they are set outside the application, before it even starts.
This is a significant improvement in comparison to the ways of keeping secrets presented above. The attacker can no longer easily grab a secret from a filesystem, as it resides in the process’ memory. A technique that uses proc interface exists, but it is not guaranteed to work. Assuming the pseudo-filesystem is mounted, the attacker can try to read /proc/self/environ or /proc/{PID}/environ, where {PID} is a natural number standing for the process ID, that must be guessed.
Although secrets are stored in environment variables, there may be easier ways for the attacker to find them. This underscores the importance of how env variables are provisioned. Think of an API key being saved to env variable after issuing the following command: export API_KEY=thisissecret. The secret value might end up in the .bash_history file. This can be avoided either by disabling command history altogether or by using of the HISTCONTROL env variable, which, when set to ignorespace or ignoreboth, prevents the command from being stored in a history file. The command must be preceded with a space character, though. Note that Bash is not alone in recording user activity. You can find environment variable values and other secrets in files created by text editors (the .viminfo file), interactive prompts (the .python_history file), and database clients (the .mysql_history file), to name a few.
Another risky situation is when env variables are set from files. To make env variables persistent across system reboots or simply to make provisioning multiple variables convenient, files like .bashrc or *.env often hold secrets. Added protection from the fact that env variables live in memory is inevitably lost. Cloud environments face similar challenges. If everybody in an organization can look up a particular service management page, where environment variables are set – the secrets become public in scope of the organization. One other thing to keep in mind is that if the application is configured incorrectly, the environment variables may end up being leaked through the error pages or through the debugging interface that is turned on.
Even securely provisioned environment variables will not stand up to an attacker who has remotely executed code through the application or who has compromised the underlying operating system in some other way. In this case, env variables can be listed using the ps utility or Process Explorer on Windows. Alternatively, the attacker can use more crude methods, such as dumping an interesting portion of a process’s memory.
Encryption management in web applications
When faced with the problem of securing data, encryption is one of the first things that comes to mind. Used correctly, encryption can supply an extra layer of data protection. However, it is not a complete solution to securing application secrets. It simply changes the nature of the problem. “How to securely store a secret” becomes “how to securely store an encryption key that protects a secret”. When consulting with our clients, the following approaches to data protection seem to dominate:
- The first is custom implementations. Some applications try to protect their secrets by using an industry standard encryption algorithm like Rijndael. However, they completely fail on the key management aspect. The secret ends up being encrypted, but the encryption keys can be found in a configuration file or in the application’s source code – in clear text. From the perspective of an attacker who can read arbitrary files from the file system, these keys are within reach. After figuring out the encryption algorithm used, it may be possible to decrypt the secrets. Even in envelope encryption schemes, where data is encrypted multiple times, there will always be a top-level encryption key that must remain in plain form. Since not everything can be encrypted, there is room for improvement in enforcing the level of privilege needed to access the keys. It would be much harder for an attacker to call a specific API on behalf of the application than to obtain arbitrary file reading capabilities.
- This brings us to the second approach, which is to use dedicated APIs that are often built into application frameworks. An example of such an API is the ASP.NET Core Data Protection. It abstracts a lot of complexity and exposes simple interface for both encryption and decryption operations. Key management aspects such as key generation, storage, and rotation are by default invisible to the API consumer. A developer with a specific use case can customize most of the settings. Default configuration options vary between deployment environments and frameworks. Therefore, it is critical to consult the documentation and understand which aspects of the process we can rely on the framework to handle. For example, an ASP.NET Core application hosted in Azure Apps will not have its encryption keys protected at rest, while the very same application launched on a Windows operating system will have them encrypted. The APIs just described can make life difficult for an attacker. However, they are not without their drawbacks, as they do not scale well and must be used with awareness of the configuration options used.
After reading this section, you probably have an idea of how many things can go wrong when storing secrets in a web application. Also, be aware that the examples given are not exhaustive. Creative attackers combine small and relatively insignificant issues into high-impact vulnerabilities every day. What’s more, today’s organizations rely on not just a few but dozens or even hundreds of web applications, often deployed in unique environments that require different mitigation options to properly address lurking threats.
Best practices for storing application secrets (at scale)
Let’s examine current best practices at a relatively high level and with the entire organization in mind. Following them will make secrets management less burdensome and reduce the attack surface. It will also make it easier to find out what happened after a security incident.
- Take the entire secret lifecycle into account
Secrets are created, then rotated (either as a planned action or in response to an incident), and finally revoked or expired. The security of the system can be weakened by neglecting any of these steps. Poorly generated secrets will not provide an adequate level of protection. The secret that is suspected of losing its confidentiality and is not rotated on time can be an excellent entry point for an attacker.
- Keep an inventory of all secrets
It is crucial to know how many secrets are in use, where they live, and who has access to them. Without this basic knowledge, you are about to become a victim of secrets sprawl. A single virtual machine hosting a web application will need a pair of SSH keys, local user account credentials, and application-specific secrets such as database credentials or cloud storage access keys, plus an optional client secret if OAuth is supported. As you begin to map other parts of the infrastructure, more secrets and associated metadata will appear.
- Allow access only to authorized clients
Enforce access control so that only clients that need a specific secret to do their job are granted access.
- Log critical operations
Because of the sensitive nature of secrets, operations such as accessing or rotating secrets should be logged. Accountability cannot be achieved without a mechanism that provides information about who accessed a particular secret and when. The log entries themselves must be protected from tampering so that timestamps and other accompanying metadata remain trustworthy.
- Encrypt your secrets
Secrets should remain encrypted at rest. When accessed over the network, TLS protection is a must. Ideally, the amount of time a secret is unencrypted should be minimized. Do not be lazy and flush that memory after a secret is no longer needed.
- Ensure availability
There is a lot to cover to have the secrets ready when needed. At the network level, avoid single points of failure and guarantee access to all clients that need it. Make sure you have regular backups that are recoverable. Finally, a versioning mechanism can help in case of accidental deletion.
- Have procedures in place
A strong technical layer is important, but it needs to be supported by a set of procedures. What is the action plan in case of a secret compromise? What if an administrative user ends up in the hospital? When the situation gets serious, the answers to these questions must be ready, preferably in the form of simple and actionable steps to follow.
As you can see, there are many facets to secure and effective secrets management. Fortunately, most of them can be solved by centralization. This comes at the cost of putting all your eggs in one basket. Despite the fact that it may seem like a bad idea, the pros far outweigh the cons. The market has quickly recognized the need for specialized software to store secrets and a variety of products has emerged.
How a vault works
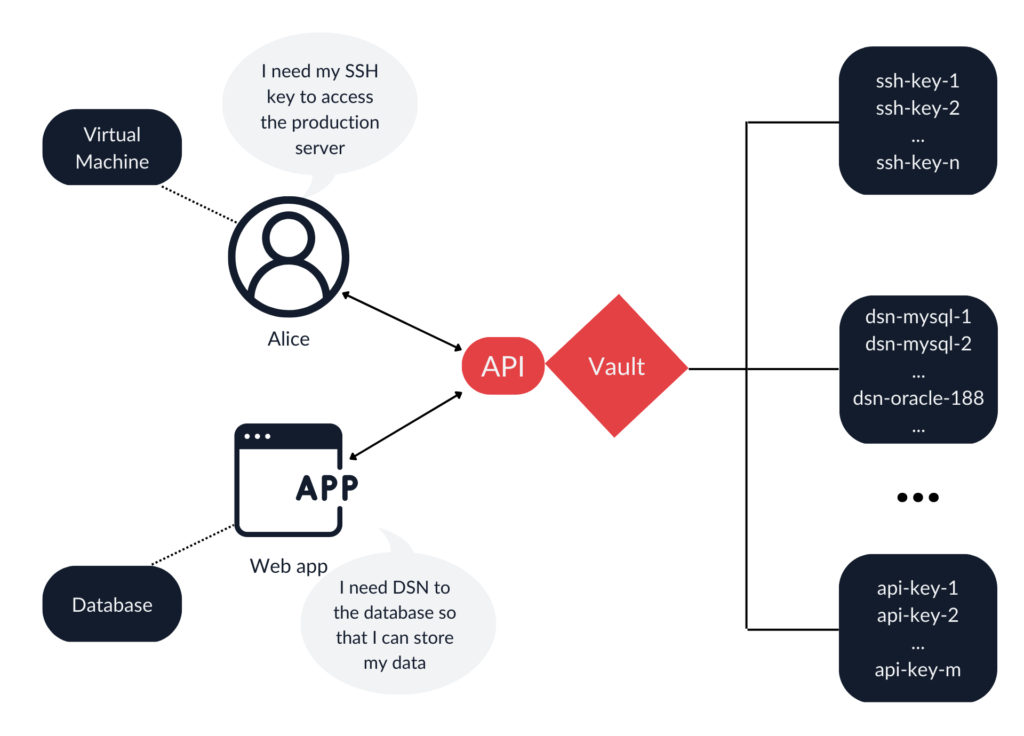
A vault is a piece of software designed to solve the problem of managing secrets. It can verify client authenticity, enforce policies that define what items an individual client can access, what set of operations is allowed, and securely store and release secrets. Many other features are often available, including centralized logging and auditing capabilities, dynamic secrets, versioning, and multiple authentication methods. It can be thought of as the equivalent of a personal password manager adapted to serve the entire organization. Users, both highly technical and regular, as well as machines, can use vaults to store their secrets.
There are many options to choose from that vary in features, deployment methods, and source code availability model.
The first two are open-source solutions with an optional paid tier that provides support and more features, i.e., high availability clustering in the case of Hashicorp Vault and auditing capabilities in the case of Conjur. Both options are cloud agnostic, which is a suitable choice for organizations using multi-cloud environments or those who prefer to host the vault in their on-premises infrastructure. At the other end of the spectrum are native cloud solutions. These are tightly integrated with the rest of their services and ecosystems. For example, the Azure Key Vault is easy to get started with because of its integration with the Visual Studio IDE. Use of the vault is encouraged by the IDE, configurable through a familiar interface, and supported for multiple programming languages. The last one on the list is a SaaS product, which offers secret management as part of their Vault Platform.
Hint: If you work in a small team or are a one-man army developer, these solutions may be overkill. In this case, you may want to try services like 1Password CLI instead.
How do you interact with a vault?
Vaults expose a public HTTP API for their users to interact with. This way, whether the user picks a web application, a direct API call, or a programming library – a vault handles the request in a consistent way. As a rule of thumb, if something cannot be done through the API, it cannot be done at all. At the time of this writing, the GCP Secret Manager does not allow you to set an expiration date for a secret via the Cloud Console. An API call or gcloud command-line tool must be used for this purpose.
Now, let’s see how to use a vault using Hashicorp Vault as an example. The supported clients are a CLI tool called vault, a web application, a programming library, or a direct API call. You may want to follow along and install vault on your machine. Keep in mind, however, that the goal of this example is to get a feel for using vault, not to provide step-by-step instructions. The simplest form of authentication, a token, will be used. We will go through the process of creating and retrieving a key-value (KV) secret.
First, use the vault command line tool to create the first secret.
user@host:~$ export VAULT_TOKEN="AAA.BBBB[...]" \
VAULT_ADDR="https://vault.someorg.com"
user@host:~$ vault kv put -mount=hello-vault secret-soup-recipe \
ingredient1=broth \
ingredient2=lemongrass \
ingredient3=shrimps
Success! Data written to: hello-vault/secret-soup-recipeThe secret called secret-soup-recipe, which happens to consist of three KV pairs, has been successfully created. The -mount flag specifies a location for the secret to live. The vault utility uses environment variables to store the authentication token needed to interact with the server. Note the presence of the space character preceding the export command. Its purpose is to prevent the token value from ending up in the .bash_history file. Finally, the precious recipe is ready to be retrieved.
user@host:~$ vault kv get -mount=hello-vault secret-soup-recipe
======= Data =======
Key Value
--- -----
ingredient1 broth
ingredient2 lemongrass
ingredient3 shrimps Extraction of individual fields is also possible.
user@host:~$ vault kv get -mount=hello-vault –field=ingredient3 secret-soup-recipe
shrimps An environment with a minimal toolset is no problem either. You can just use a curl command to get its secrets. This is the true manifestation of the API’s flexibility.
user@host:~$ curl -s $VAULT_ADDR/v1/hello-vault/secret-soup-recipe \
--header "X-Vault-Token: $VAULT_TOKEN" | jq '.data'
{
"ingredient1": "broth",
"ingredient2": "lemongrass",
"ingredient3": "shrimps"
} This all looks good, but you may want your application to communicate with the vault instead of typing CLI commands. How much code change is needed? There is a minimal example written in Go that uses the official client library to read and write a secret. See the hello-vault-go repository for details.
What are the main benefits of using a vault?
A keen eye might notice that we still need to be authenticated in order to interact with the vault. How does that make sense? Aren’t we just replacing one credential with another? Technically yes, we are. Secrets management solutions will not make the secrets disappear; they will rather help us harness them. Here are the reasons why, in this case, an authentication token is much better than having an actual secret stored somewhere with the application:
- The token itself does not have much value. It must be exchanged with the server for a secret.
- Tokens are subject to policies that can enforce how many times a token can be used, when it expires, and so on. Policies can go beyond token attributes to allow clients to perform exchanges only from a specific IP address or during a specific time of day.
- We can invalidate any token in the organization from a single location. This reduces the chances of not being able to locate the owner of the secret and not being able to act quickly.
The advantages of using vaults do not end at the secret-retrieval stage. Consider a scenario in which multiple microservices share a single database. They share the same database connection string (sometimes called a data source name, or DSN) and use their individual tokens to authenticate to the vault. If one of the microservices is compromised, it is very easy to pinpoint the source of the incident. If they were simply sharing a hardcoded DSN, all database clients would have to be investigated. The vault’s logging and auditing capabilities will be greatly appreciated by blue teams and help meet regulatory requirements. Logs contain information about when, who, and what was accessed. This can be invaluable if token misuse is suspected.
Last but not least, there is this concept of dynamic secrets. The way it works is that a secret does not exist until the client requests it. That is a very welcome feature because an attacker obviously cannot steal something that does not exist. Most web applications these days use databases to persist their data. Using dynamic secrets, an application can request a brand new DSN from vault every time it is deployed. Under the hood vault holds a preconfigured database account with permission to manage database accounts. When the application needs credentials, the vault connects to the database, creates expirable credentials, and passes them to the application. In addition, the application can revoke the credential after use to further shorten the lifetime of the secret. After revocation, the temporary account within the database is deleted.
Why do vaults give attackers a hard time?
Now, when we have a better understanding of some of the key benefits of a centralized secrets management solution, let’s put this in a practical context. An attacker has exploited a vulnerability in an application and learned the value of the VAULT_TOKEN and VAULT_ADDR environment variables from the preceding example. The goal is to perform lateral movement activities and preferably escalate privileges. The next step after finding the values of the env variables is to make a request to the Vault HTTP API and exchange the token for a secret. This would be possible if the following conditions are met:
- The vault is accessible from the public network. Otherwise, the attacker must force the server to send the request on their behalf. The vulnerabilities that would need to be identified and then successfully exploited are remote code execution (RCE) or the severe variant of SSRF, where the request headers are under the control of the attacker.
- The stolen token’s time-to-live has not expired, the token’s operations limit has not been exceeded. The exchange has to comply with the configured policies that affect the retrieval of secrets.
In addition, vault maintains detailed logs to assist blue team operators in their anomaly detection and incident response processes. In the event of a confirmed breach, the VAULT_TOKEN can be immediately revoked, and it is easy to determine if the compromised token has been exchanged for a secret. Furthermore, credential rotation only affects the application instances that have been breached – not their entire pool.
Many of the benefits of vaults require initial configuration. Understanding the configuration options available and following best practices is an investment that will pay dividends in the future. To achieve their endgame, attackers must go to great lengths to bypass additional layers of protection.
Steps to take before you commit to a vault
Sometimes I find myself jumping right into a project rather than thinking it through. While this proactive approach is often beneficial, for a more complex endeavor such as implementing a secrets management solution in your environment, I would recommend a more stoic approach.
- Familiarize yourself with a few products, then decide which one best meets your needs. Understand its limitations and get to know it well. This will not only make for a smoother implementation, but it will also make it more likely that other members of your organization will see the value that vault has to offer.
- Review the best practices from the previous section and invite others to a brainstorming session. Have these procedures ready. If you decide to host vault externally, make sure that an ISP outage will not ruin your operations, which might otherwise function just fine without an Internet connection.
- Start with the vault of your choice for new deployments and migrate legacy deployments as you go. This solution can be implemented incrementally, one application at a time.
Summary
This article began by exploring the places web applications use to keep their secrets of various kinds. Each of these locations differed in their resilience to an attacker who had gained an initial foothold and was able to read files from the applications’ underlying file system. Then the net was cast wider, and the focus shifted to best practices for storing secrets in more than one application, as this is a far more typical use case that organizations face today. Finally, vaults were explored, seasoned with a bit of common sense regarding the actual use of one.
Secrets are undoubtedly difficult to manage and storing them in the application itself is risky. While young organizations and those with a strong cloud presence tend to embrace vaults, there are still many computing resources out there that are stuffed to the gills with secrets. I look forward to vaults becoming a common sight in the networks we traverse, and attackers realizing that compromising a secret is now just the beginning of the game.
If you need assistance in securely storing secrets for your solution, use our contact form. Also, feel free to reach me out – you can find me on Twitter or LinkedIn.