
HTTP request smuggling attack. Is it a vulnerability still worth considering?
Understand the foundations and the current landscape of Request Smuggling attacks in order to protect against it. Our recommendations will help to mitigate risks and secure your solution.




HTTP request smuggling attack. Is it a vulnerability still worth considering?
Smuggling through international borders is a massive-scale problem. History has shown people can smuggle everything, from drugs, money, and small animals to even people inside a car seat. Mr. Goldfinger had smuggled gold as body castings on a Rolls-Royce Phantom III, which would be later re-smelted once they arrived at the destination. Smuggling has no limits to the imagination, yet, the best smugglers are the ones we don’t know about.
There is a similar problem in the digital world. There is an attack called HTTP Request Smuggling, which has devastating consequences. Depending on the case, it might result in the application’s desynchronization, ruining each user’s experience. This attack is quite old; it has been patched countless times since then, only to emerge every now and then.
General recommendations to prevent request smuggling
How to mitigate this attack? Either you have heard about potential consequences already but never had the time to get a closer look, or you are reading a penetration test report of your application that mentions the vulnerability. Nevertheless, worry no more because this is the right time and place. This article will cover a basic understanding of this vulnerability, its evolution, its consequences, and how to defend against it. Below are a few recommendations – although we recommend reading the whole story for better understanding.
Request smuggling mitigation in HTTP/1.1:
- Avoid writing your reverse proxy – as usual, ready-to-use and thoroughly tested solutions are best in terms of security;
- Some products have an insecure default configuration (for compatibility purposes), make sure to read the documentation thoroughly;
- Reject requests older than HTTP/1.1, since older HTTP versions have unpatched vulnerabilities;
- Drop requests (and close the connection) with malformed headers, specifically if a malformed header is on the list of forbidden headers;
- In case you are responsible for implementing an HTTP server, use RFC 7230 (2014), not RFC 2616 (1999) – the older standards are more “liberal” in parsing HTTP requests, which does not align well with security;
- Normalize ambiguous requests – while a request that has duplicate headers may seem like an innocuous mistake, there is a problem when your backend interprets it differently than the frontend. Therefore, the backend should always receive the same request that fronted “understood”, dropping any ambivalent requests.
Additional considerations for HTTP/2:
- Remember that HTTP/2 is under active research regarding HTTP Request Smuggling and other parsing attacks. While the protocol is secure against most parsing ambiguities due to its binary nature, the text-protocol HTTP/1.1 might be used as a fallback option. Because of that, all HTTP/1.1 recommendations also apply;
- Most attacks based on downgrades to HTTP/1.1 are only possible when a proxy talks HTTP/1.1 to the backend. Consider using HTTP/2 for communication between proxy and end-servers – it will make these attacks unfeasible.
Increase in HTTP request smuggling vulnerabilities
Let the numbers speak for themselves. The chart presents a substantial increase in HTTP Smuggling vulnerabilities over the years:
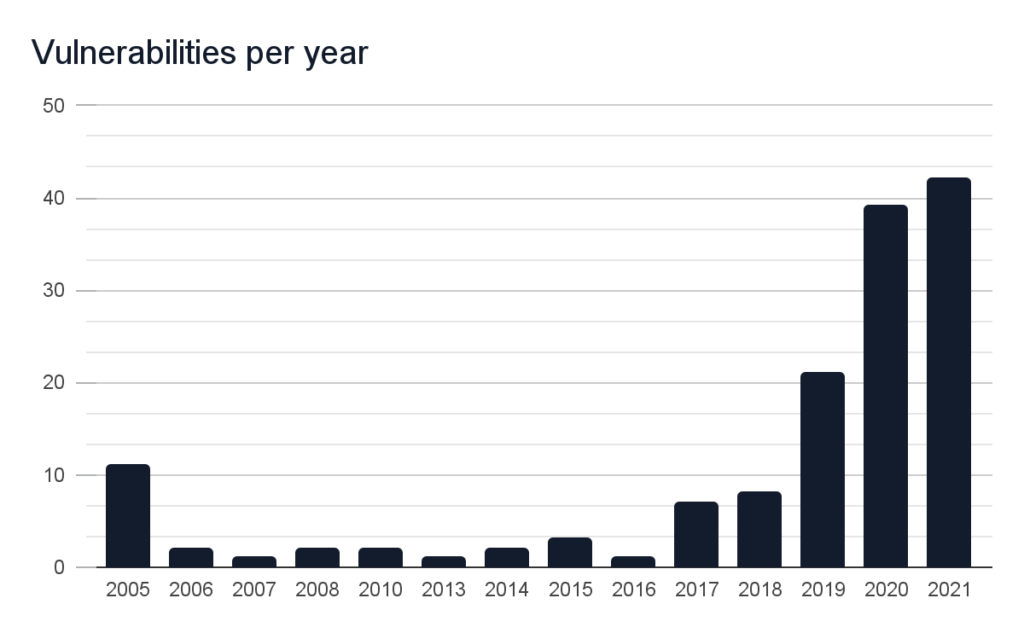
About 160 vulnerabilities have been found in 213 products of over 90 companies of all sizes, including names known to everyone. Precisely, the vendors that were vulnerable include:
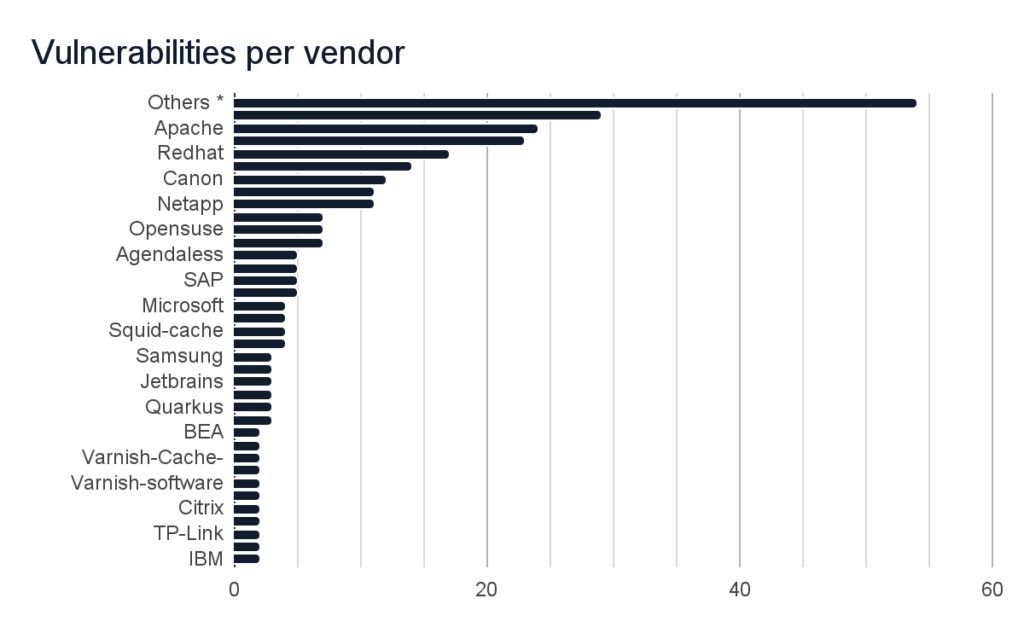
* Other vendors, that had 1-2 related vulnerabilities discovered in their products, include: Joyent, Kamailio, Pulsesecure, FUCHS, Suse, Mattermost, Python, Aeroadmin, Ikarussecurity, Rust-lang, Sylius, Palletsprojects, Linuxfoundation, Haproxy, Imperva, Ruby-lang, Parseplatform, Silverstripe, M-files, Tiny-http-Project, Pingidentity, Mcafee, Zeek, Ssl-explorer, Celluloid,D-Link, Perl, Ohler, Meinheld, Goliath-Project, Eclipse, Apple, Bottlepy, F5, Cloudfoundry, HP, ASUS, Djangoproject, Hive, Veridiumid, Siemens, Actix, Openresty, Find-my-way-Project, Sensiolabs, PEPPERL, SonicWall, Varnish-cache, Gin-gonic, Fortinet, Huawei, Getcujo, Objectcomputing, Lightbend.
The trends are surging, making now the most suitable time to understand this vulnerability and how to protect against it, which the following sections will cover.
Request smuggling explained
Let’s think about space. No, not the interplanetary one you have seen in the Star Wars series, but rather the slim-ruler-shape keyboard button right under your fingers. How dangerous can it be?
In fact, there are cases where the mentioned keyboard button can cause havoc. Not in the physical sense, since we are currently in the security space, not criminology, aren’t we? Additionally, space is not the only invisible enemy here, as there are other non-printable characters we can include in HTTP requests. The way the HTTP server reacts to these bytes is not critical to the attack, but the difference between server and proxy behavior is. Although there is a common standard, it is implemented by developers according to their interpretation. And that is not always accurate. Furthermore, standards are often not 100% bulletproof themselves.
Let us move to the alternate world where the post office is people-work powered. Imagine you are a post office worker and work on the production line: standing at the end of a long mail queue, you sort them into different boxes – so they go into places. There are no envelopes in this world; each letter is folded, and inside there is an address (upper half) and content (bottom). You don’t read the content – that would be rude. Out of the blue, when you are trying to unfold the letter, you notice it’s cut right in the middle. You have only the address but no content. What to do? Was the machine hungry? The shift supervisor is snoring loudly, and you must decide – should you wait for the next part or assume somebody just wanted to ping their relatives? So you pass the letter as you found it.
In all that chaos, when the mail arrives at the next post office, they will have the same doubts. Hopefully, they disagree with our previous post office for the sake of this example because that would be a perfect instance of request smuggling. The worker receives that same letter cut in half with only the address and decides that any letter that comes through next must be the missing part. He won’t open the following letter because it all makes sense now – just take duct tape, make it one, and pass it over. Job well done – the world is safe now. And the promotion from shift supervisor is in order.
Only it isn’t.
Classic request smuggling example
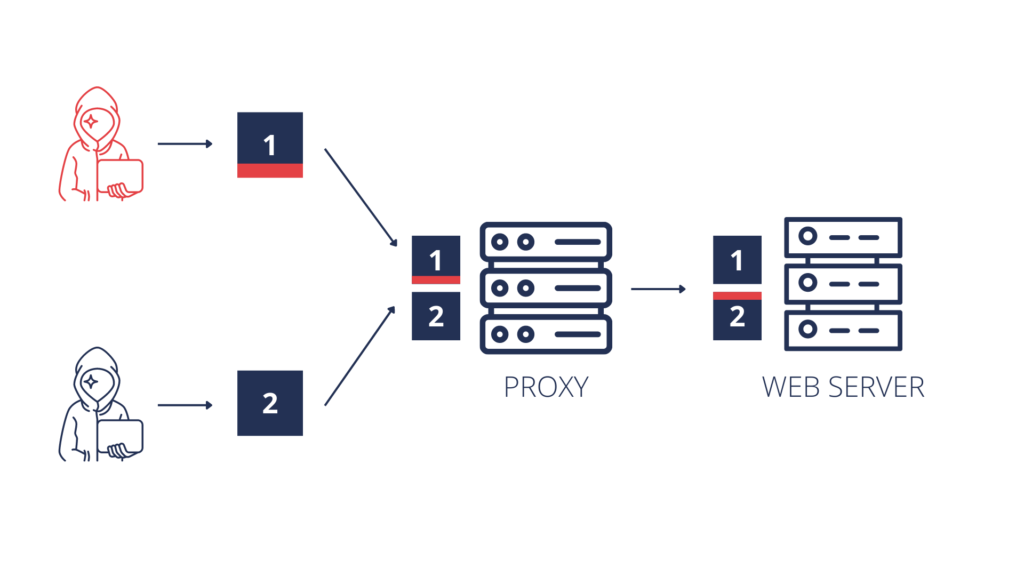
The biggest issue with this vulnerability is finding the faulty party. It is neither the server nor the proxy since only a combination of chosen proxy and backend server behavior makes perfect conditions for this attack. As an example, let us see a classic technique that is simple enough to understand the fundamentals of this attack. Consider the following HTTP request:
POST / HTTP 1.1
Host: example.com
Content-Length: 6
Content-Length: 5
12345GIt seems we have a duplicate header, or maybe it’s just a mistake? Next request in the line is sent by innocuous user who wants to post their comment:
POST / HTTP 1.1
Host: example.com
Content-Length: 22
comment=MyFancyCommentWhile the request does not seem ominous, the response the user receives may not quite fit:
"Unknown method GPOST"What just happened? Was it some improper word? Did the router die again? And for what it’s worth, what method is GPOST? And have I just lost my remarkably accurate comment?
And unfortunately, the only answer the user receives is for the last question, and the answer is yes. From a technical perspective, the request reached the first post office worker – proxy. Proxy reads the first Content-Length, strips that header and passes the request. Another post office worker – backend – reads the request, only to see that it is too long – based on Content-Length: 5 – so the backend cuts it right after the 5th byte. The application expects parameter comment, instead gets payload 12345, returns an error here. Last byte of the attacker’s request that was cut off gets glued to the beginning of the next request, just like the letter in the post office example. And hence comes the GPOST, that the application does not know how to handle.
Is Request Smuggling really dangerous?
Above technique is known as the Content-Length:Content-Length variant of HRS attack, or CL:CL. Although this particular technique serves as a good explanation and is not a threat anymore, there are many other variants discovered over the years. Most of them use Transfer-Encoding header combined with Content-Length header, that lead to CL:TE and TE:CL attacks, or use Content-Length with value 0, despite providing the actual request payload – the goal is to find combination that leads to difference in parsing HTTP requests between two or more parties receiving it.
The research is on – there are plenty of references to read on in the last section. Now, consider that “breaking the application” that leaves a user with his comment lost forever is not serious enough, let us quickly estimate what else can go wrong here:
- When proxy serves as a cache, we could poison it and serve our content to all users;
- While posting a comment, a description on our profile, or anything similar, we could specify a much larger Content-Length than our request, so the follow-up user’s request will be appended to our comment, together with all cookies and tokens;
- We could serve XSS attacks to random users across the application, amplify other attacks, or just break the experience for any user;
- Desynchronisation also means that the HTTP server might send your response to a different user – together with all sensitive information it contains;
- There is much to learn about the victim’s internal network by bypassing access control. We could contact internal services, find out headers that are being sent behind proxies to internal servers, and rewrite them to cause more havoc – with endless possibilities.
And these are just a few examples.
HTTP server headers parsing quirks
Standards inconsistencies leading to loose HTTP server implementations are critical to HTTP Request Smuggling
If you could ask your web server in what form it would like requests to be served, the answer would probably be – any parseable, decent-looking way. Since it is a machine, it would not care less about what appears on its plate. Any digestible input it gets, it will process. And that is where standardization comes in. RFC 2616 for HTTP/1.1 (defined in 1999) was the primary source of knowledge for implementing HTTP servers.
Mind a whitespace before a colon in a HTTP request
There was one problem, though. Jon Postel’s law, also known as the robustness principle, says: “Be conservative in what you do, and liberal in what you accept from others”. It has been important for building the fundamentals of the Internet. Although loose standards and liberal implementation may accelerate the development, they will not help you secure it. And that is why, in 2014, a new RFC for HTTP/1.1 was proposed – RFC 7230. It is still a thing, and that is because it has a much more careful approach. Take our favorite whitespace, for instance:
“No whitespace is allowed between the header field-name and colon. In the past, differences in the handling of such whitespace have led to security vulnerabilities in request routing and response handling. A server MUST reject any received request message that contains whitespace between a header field-name and colon with a response code of 400 (Bad Request). A proxy MUST remove any such whitespace from a response message before forwarding the message downstream.”
This means if your server receives an HTTP request with one of the following headers:
Content-Length : <number>
Content-Length\t: <number>
Content-Length : <number>It has to reject the message. Why? Simply because this space might cause some servers to interpret this Content-Length, others to pass it, and others to reject it. That difference in behavior in two or more servers is essential for the attack. The question remains whether RFC does cover other attack techniques as well. For instance, let’s put our black hat on and think of some different variants:
Content-Length: +1234
Content-Length : 1234+1234
Content-Length : 12 34
Content-Length abcd: 1234Or even:
Content\rLength: 1234The last idea is especially creative and depends on whether the HTTP server does the upper-casing of parsed headers, which some servers do. If it does so incorrectly, then “uppercased” \r will result in ‘-‘, which would be perfectly compliant with specs (‘\r’ | 0x20) == ‘-‘). And that is just one header with a few variations, but there are definitely other possibilities too.
Why HTTP Request Smuggling is difficult to defend
We have prepared a few real cases where simple bugs lead to serious Request Smuggling vulnerabilities. These fragments explain how HTTP servers parse the request and how difficult it is to spot the vulnerability. Below there is a fragment of parsing HTTP headers in gunicorn, a popular Python HTTP server:
1 curr = lines.pop(0)
2 header_length = len(curr)
3 if curr.find(":") < 0:
4 raise InvalidHeader(curr.strip())
5 name, value = curr.split(":", 1)
6 name = name.rstrip(" \t").upper()
7 if HEADER_RE.search(name):
8 raise InvalidHeaderName(name)In this case an attacker could smuggle a filtered header name by appending a whitespace to its name. While the authors fixed this vulnerability simply by removing rstrip at line 6 (which they would still allow through a particular, non-default setting and warn users about possible exploitation), they would still need to drop the request and response with 400 code to be fully compatible with RFC 7230. On a side note, this is a fix that a few other vendors [1][2][3][4][5] decided to implement. But then, another issue came up in different place:
1 def set_body_reader(self):
2 chunked = False
3 content_length = None
4 for (name, value) in self.headers:
5 if name == "CONTENT-LENGTH":
6 content_length = value
7 elif name == "TRANSFER-ENCODING":
8 chunked = value.lower() == "chunked"
9 elif name == "SEC-WEBSOCKET-KEY1":
10 content_length = 8
11 if chunked:
12 self.body = Body(ChunkedReader(self, self.unreader))
13 elif content_length is not None:
14 try:
15 content_length = int(content_length)
16 except ValueError:
17 raise InvalidHeader("CONTENT-LENGTH", req=self)
18 if content_length < 0:
19 raise InvalidHeader("CONTENT-LENGTH", req=self)
20 self.body = Body(LengthReader(self.unreader, content_length))
21 else:
22 self.body = Body(EOFReader(self.unreader))The server iterates over received headers and sets appropriate values. All would be fine if it weren’t for the case where the request might, for some wild reason, contain duplicate header names with different values. Say this serves as a frontend, so assuming the backend does not accept duplicates (uses the first encountered value), this will successfully desynchronize your application. RFC says “The recipient MUST either reject the message as invalid or replace the duplicated field-values with a single valid Content-Length (…)”. A more explicit patch is to reject the message altogether. Finally, some vendors do not implement countermeasures by default, leaving it as a non-default option that could be configured.
Transfer Encoding and other critical headers
Transfer-Encoding is another header that helps HTTP servers interpret the length of requests. It has one interesting value, chunked, which causes HTTP requests to be split into chunks. Some servers might interpret this request differently based on its value and hackful variations. Think about other headers, such as the X-Forwarded-For with value 127.0.0.1, which may help to bypass security controls. It tells the server that the received request came from the server itself, so why shouldn’t it give access to the requested admin panel? Most WAFs will block this behavior, but not necessarily when the header is obfuscated using the same techniques.
The main lesson here is that many different headers might get exploited using similar techniques. Even though it won’t be exactly called Request Smuggling, it is not really a problem for a creative attacker.
The standard, guidelines, and general knowledge will probably cover some cases, but will they protect you from all techniques? History has a simple answer. And that is why regular penetration testing is essential. No standard will ever cover your specific set-up. Regular testing is the best assurance of decreasing the number of possible bugs, which applies to every kind of software. Also, caution is highly advised since these tests might desynchronize HTTP traffic in your application. Preparing a replicated test environment might help, but will it be identical to the production environment? That also must be considered; otherwise, tests would not make practical sense.
HTTP/1.1 & HTTP/2.0 under attack
HTTP Request Smuggling, or HRS, is a remarkable attack technique based on inconsistencies in the interpretation of HTTP requests by one or more intermediate proxy servers. The attack has recently been in the spotlight thanks to a thorough research by Regilero, James Kettle, and others [1][2][3], also covered in detail on PortSwigger’s blog.
PortSwigger also gathers a community-powered list of top-innovative security research on their blog once a year. Last year’s iteration was focused explicitly on HRS and other HTTP parsing vulnerabilities.
While most researchers exploit a specific set-up, others want a more systematic approach to discovering attack techniques with differential fuzzing. The method is called so because it attempts to cover every possible combination of malformed input while considering every header in use. With the help of statistics and technical analysis, responses are categorized based on their relevance to potential exploitation.
While HTTP/1 is the main subject of the attack as an ASCII-based protocol, HTTP/2 is also under attack [1][2]. HTTP/2 prevents all kinds of HTTP Request Smuggling simply through its structure (header names, their values, and even entire requests are separated on a binary level). On the other hand, the frontend often downgrades the connection to HTTP/1 communicating to the backend. Toolset, techniques, and general approaches are different since attackers now need to smuggle HTTP/1 syntax inside HTTP/2 requests, but the effects on the application are identical. There were also proposals to split HTTP/1 traffic on a network layer, which is basically now solved by HTTP/2 implementation.
Additionally, a proxy server is not required to make this attack possible. The user’s browser can also send malicious requests that cause desync in single-server scenarios. This approach is called Client-Side Desync (CSD). Attack methods and effects on the application are similar to traditional HTTP Request Smuggling attacks. Only now, instead of sending malformed requests hoping they might get interpreted differently by proxy and backend, we send an almost-perfectly RFC-compliant sequence of HTTP/1 requests with a timeout between them. Another technique includes exploiting the HTTP/1 connection reuse feature: sending two requests down the line, one in the body of the other while targeting an endpoint that ignores the Content-Length header. All the techniques have something in common – the pivot of the attack is moved from proxy to the victim’s browser, leaving a whole new attack surface to explore.
Summary
This article has covered the story of Request Smuggling attacks starting from their discovery in 2004, through its evolution to a future perspective. The main goal was to understand techniques currently in use to help defend against such attacks or mitigate their consequences. HTTP/2 is the ultimate solution to most of the problems discussed here; however, only when it’s implemented end-to-end, from the client, through proxies, to the backend. Recently, more and more vulnerabilities are being discovered thanks to downgrading connection to HTTP/1.1, which many proxies do by default. As to HTTP/1.1, we recommend using HTTP servers that are RFC-compliant, meaning they need to normalize ambiguous requests and drop malformed ones. Finally, have your application regularly tested – since recently, there has been a surge in the exploitation of HTTP parsing ambiguities. New techniques are being constantly discovered, and after so many years, the Request Smuggling attack is still alive and well.
In case you would like to discuss the topic further, feel free to use our contact form. You can also find me on Twitter or LinkedIn.