
Voice Biometrics – how easy is it to hack them with AI Deepfake?
Voice biometrics are becoming a widely used authentication method. They may be convenient but also vulnerable, especially in the age of AI. Here, you will find my research regarding voice biometrics security.




Voice Biometrics – how easy is it to hack them with AI Deepfake?
Voice biometrics is a process of authenticating the user by the sound and characteristics of their voice. It promises to deliver high accuracy, low cost and great UX improvements compared to old-fashioned authentication methods. Even though at first voice biometrics can sound like a godsend, wise man once said, “Everything in life has its price”. Can you really improve user experience and make the authentication more seamless without also making a sacrifice on security? In this article, I will share how voice biometrics can be fooled with commonly available tools for creating AI Deepfakes.
Voice biometrics – how does it work?
Before we begin, let’s familiarize ourselves with how the process of verifying user based on their voice works in the first place. As an additional exercise, while reading the paragraph below, try to find similarities with known and loved fingerprint authentication.
At its core, there are two main, independent phases: enrolment phase and authentication phase. The former consists of gathering the user’s voice and generating so-called “voiceprint” – an object stored in system’s database and used to compare your voice with. The latter, authentication phase does exactly what it says. During this phase the user is asked to provide their voice sample, either by speaking freely or reciting a pre-defined phrase. Gathered audio is compared to the voiceprint and access is granted or denied. A visualization of the whole process has been presented below.
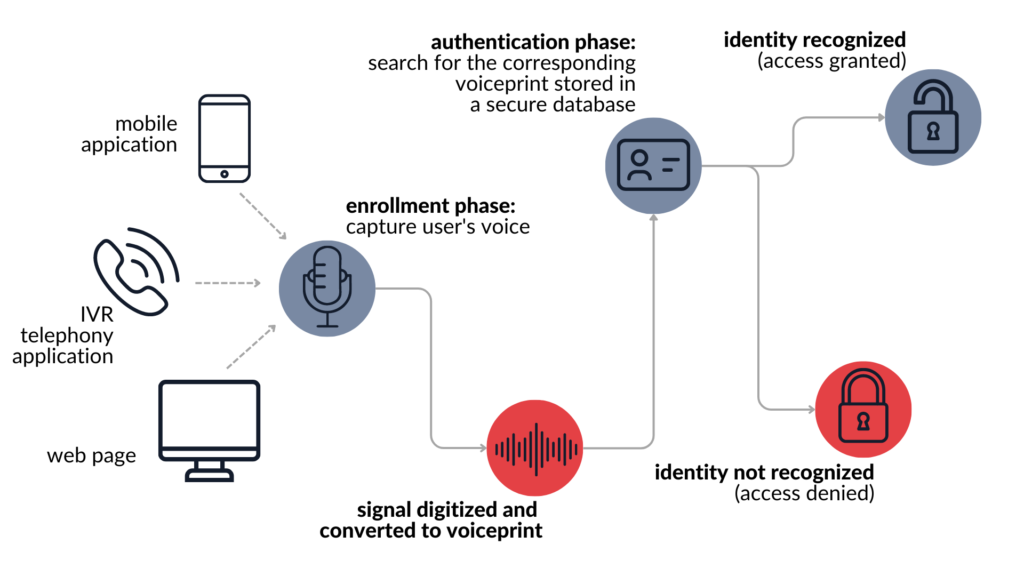
As you can see, the whole process is comparable to the fingerprint authentication found in almost every mobile phone. At first, to begin using your finger as a password, you need to set it up by placing it on the sensor multiple times in various positions (enrolment phase). Only after this process is completed, a scan of your fingerprint can unlock your phone (authentication phase).
What can go wrong with voice biometrics – quick threat modeling
Firstly, let’s set some boundaries for ourselves – the hypothetical attackers. Let’s assume that the system is being targeted by a low-skilled attacker without expert knowledge and advanced tools. Heck… let’s say the attacker doesn’t even own a microphone. All they have at their disposal is an online tool for generating deepfake voice based on a pre-recorded sample. Yes, that’s really all our attacker has up their sleeve. No fancy fuzzing tools, no audio manipulating software, no twisted techniques – just an internet browser and a dream.
Now, let’s take a look at the use cases of voice biometrics solutions. After all, we need to place the technology in the correct context. Digging into press releases of some of the most popular voice biometrics providers, we can get a pretty good overview of the industries utilizing this technology. Call centers and helpdesks seem to be the most prevalent target and it absolutely makes sense! It’s easy to imagine time and money savings for a company if a caller can be authenticated by a robot within the first few seconds of the call. But there’s one caveat that might come to the rescue for the attacker – quality of audio when a call is made through a cellular network.
Time is running out and we’re left with one question: “Can an attacker use worsened audio quality to his advantage in the context of voice authentication?”.
Connect with our Threat modeling Expert!

Does audio quality matter for voice recognition?
Yes, absolutely! Going back to the call center example, one can safely assume that most, if not all, calls will be made through a cellular network. Do you remember that screeching yet muffled sound of hold music while you’re waiting in a queue trying to make an appointment? Yeah, same thing happens to your voice while on a call.
If hold music can lose so many of its features, how does your voice compare? Let’s investigate. As of writing this article, the most prevalent and used speech codec for phone calls is AMR-WB with the maximum bitrate of 23.85 kbps. A good visualization is presented below, where my voice sample can be heard as it was recorded on a low-budget microphone. Next, there is an exact same sample compressed and with its bitrate reduced to 24 kbps. Consider using headphones for better results.
You can clearly notice the lack of voice clarity and distortion of certain voice features. Compared to the full quality sample, compressed one feels like it was recorded by a completely different microphone shoved somewhere in the cabinet far away from my desk.
Generating a deepfake voice to fool voice biometrics
To train our AI model, we need an input voice sample. Ideally, to be as objective as you can, the said sample should be as close to being a random text as possible. For the purpose of this case study, I went with reading a random book sample. So, a following fragment from the popular novel “In Desert and Wilderness” by Henryk Sienkiewicz has been recorded and uploaded into the ElevenLabs’ Instant Voice Cloning technology:

In total, 57-second-long voice sample has been created. It contains 147 words in total, 104 of them being unique words. At a glance, that doesn’t sound like it’s good enough to generate a full-fetched imitation of my voice, but let’s not lose hope. To my surprise, such a relatively short voice sample resulted in a crisp and clear deepfake that sounds close to my real voice if not for the visible accent difference. Hear it for yourself 😉
Testing targets in search for vulnerabilities to deepfake attacks
To remain as objective as possible and in order to test the technology as a whole, 4 different voice biometric solutions providers were picked. “Picked, how?” you might ask. Googling phrases such as “voice biometric solution” and selecting some of the top-resulting links was the algorithm of choice.
While there are some nuances across different solutions, they all work basically the same. At first, the system needs to generate a “voiceprint” – a structure unique to your voice and used to compare with the voice sample gathered during authentication attempt. During this phase, two of the chosen platforms require the user to read a specific text, while the other two just ask you to speak freely whatever comes to your mind.
After that, everything comes to a critical authentication phase. Here, your role as a user is to provide a voice sample that will be later compared with the “voiceprint”. Again, for two systems, you need to read a system-specified message out loud, and for the other two, just the sound of your voice when speaking freely is sufficient.
Testing a single provider consisted of 3 steps. After completing the enrolment phase with my real voice, a single authentication attempt was also made using my unaltered voice to check whether the system would recognize me correctly. Upon confirmation, an additional rogue authentication attempt was made – this time, utilizing the deepfake clone of my voice.
Since the purpose of this article is to show the quirks of voice biometrics mechanism as a whole and not the implementation of a specific solution, the names of our testing targets have been redacted. Instead, they will be listed as Provider A, B, C and D.
Biometric voice recognition vs High quality audio
Alright, first, let’s give the technology some advantage. During this round of tests, all voice samples provided were uncompressed and taken straight out of a voice recording software or an online deepfake generator.

In a nutshell, we’ve achieved a 75% success rate for an attack that requires 5 minutes of work. That doesn’t inspire confidence. A Proof-of-Concept demo has been presented below. Check it out and determine whether you could’ve been fooled if you were the not-so-artificial intelligence behind the voice biometrics engines.
Although the voice is very similar, there are some notable differences between my real voice and the fake one. One of the solutions managed to detect my deepfake and label it as a voice of an impostor. Let’s see what happens when we dramatically reduce the audio quality.
Voice biometric solutions vs Compressed audio
But what about our call center example from before? This time, all audio samples had their bitrate reduced to 24 kbps before uploading them to the voice biometrics software as to mimic the loss of quality when using the AMR-WB audio codec.

Unfortunately, all the tested solutions failed to detect the deepfake of my voice correctly, and to be honest, I’m not that surprised. The quality of the voice is so bad, and so much of the detail has been lost that I imagine that even for me, it would be hard to detect a deepfake of my own voice. Again, take a look at the Proof-of-Concept video below.
As you can see, the audio quality really does matter when it comes to voice biometric authentication. This round of tests can be a great lesson for organizations integrating the said solution within its product. In general, try to gather voice samples through a mechanism which provides as high audio quality as possible (e.g., through a mobile app sending voice to the API, not a cellular network using low bitrate).
Tips for secure voice biometrics usage and implementation
For organizations integrating voice biometrics
When thinking about integrating voice biometrics into your project, an organization needs to clearly establish the context of its use. Perform threat modeling with that context in mind. Think about any limitations or features that might make the authentication less reliable. Establish what type of data or level of access a potential attacker can gather when hijacking someone’s voice with a deep fake. Try to optimize the false acceptance rate to maintain the usability but do not compromise on security of the product. As an organization, assume that false positives will happen, no matter what. Can your solution accept that inevitability? If not, consider using voice biometrics only for user identification and not authentication. As always, maintain your defense-in-depth approach, especially when using voice biometrics. Treat it as one of many layers of security in your project and do not treat it like it’s the key to every door. Last but not least, do not assume that a given voice biometrics solution is secure based only on the provider’s claims. Perform a penetration test to get an unbiased security review of your product.
For voice biometrics users
I’ll be honest – I find it hard to give any general tips for the users in general. The reason is simple, every one of us uses his/her voice in a different way and is willing to accept different levels of risk.
One thing can be said for sure. Is your voice readily available because you’re a podcaster, a public speaker, or a politician? Let me be blunt – you’re exposed to much greater risk than an average Joe. The attacker already has a sample large enough to deepfake your voice and even if they don’t, collecting a sample of your voice through vishing seems like a trivial task.
Treat this as an exercise, perform your very own (and maybe very first 😉) threat modeling and ask yourself – “Am I willing to accept the risks?”. For your threat modeling to be seamless, you may watch our YouTube series about instant threat modeling.
Summary
We have proven that by using a short sample of the victim’s voice, we could bypass the most common voice authentication solutions. Let’s revisit the question from the beginning of the article – “Can you really improve user experience and make the authentication more seamless without sacrificing security?”. Unfortunately, it’s not that easy. This doesn’t mean that you should avoid voice biometrics like it’s the plague. The key is the context of use and what data a potential attacker can gather when a false-positive authentication eventually happens. That’s right, it’s not a matter of if but rather a matter of when.
The point, which my colleague Sebastian proved on our blog over 2 years ago when researching face recognition authentication still stands to this day – “Biometric always means probabilistic and it is never 100% bulletproof”. With the rapid development of AI voice emulators, we’re approaching the point where the whole debate revolves around a simple question – “Who’s got better AI?”
A good analogy to voice authentication is handwritten biometric recognition – a technique of identifying a user based on their handwritten text. You can imagine that given a large enough sample, someone skillful enough could forge a banking cheque with a fake signature and transfer your funds. The same principles apply here. Treat your voice with the same mistrust as you do your own handwriting.
Additionally, please keep in mind that this case study was conducted without using any advanced tools and techniques that we usually involve while performing penetration tests of voice biometric solutions. Deepfake is not the only attack vector that might be used by an attacker to weaken the security of your product.
Connect with our Expert!
For over 20 years, Securing has been helping the finance industry safeguard apps, networks, and services. If you’d like to discuss the security of your product or service, simply book a call or complete our contact form – we’ll get back to you shortly.
